


Figure
1.
Physical picture and the internal flow channel design of the spray cold plate.
Gaussian graphical models have been widely used for network data analysis. Although various methods exist for estimating the parameters, simultaneous inference is essential for graphical models. In this study, we propose a bootstrap procedure to conduct simultaneous inference for Gaussian graphical models. The simultaneous inference procedure is applied to large-scale graphical models and allows the dimension of the parameter vector of interest to exceed the sample size. We prove that the simultaneous test achieves a pre-set significance level asymptotically. Further simulation studies demonstrate the effectiveness of the proposed methods.
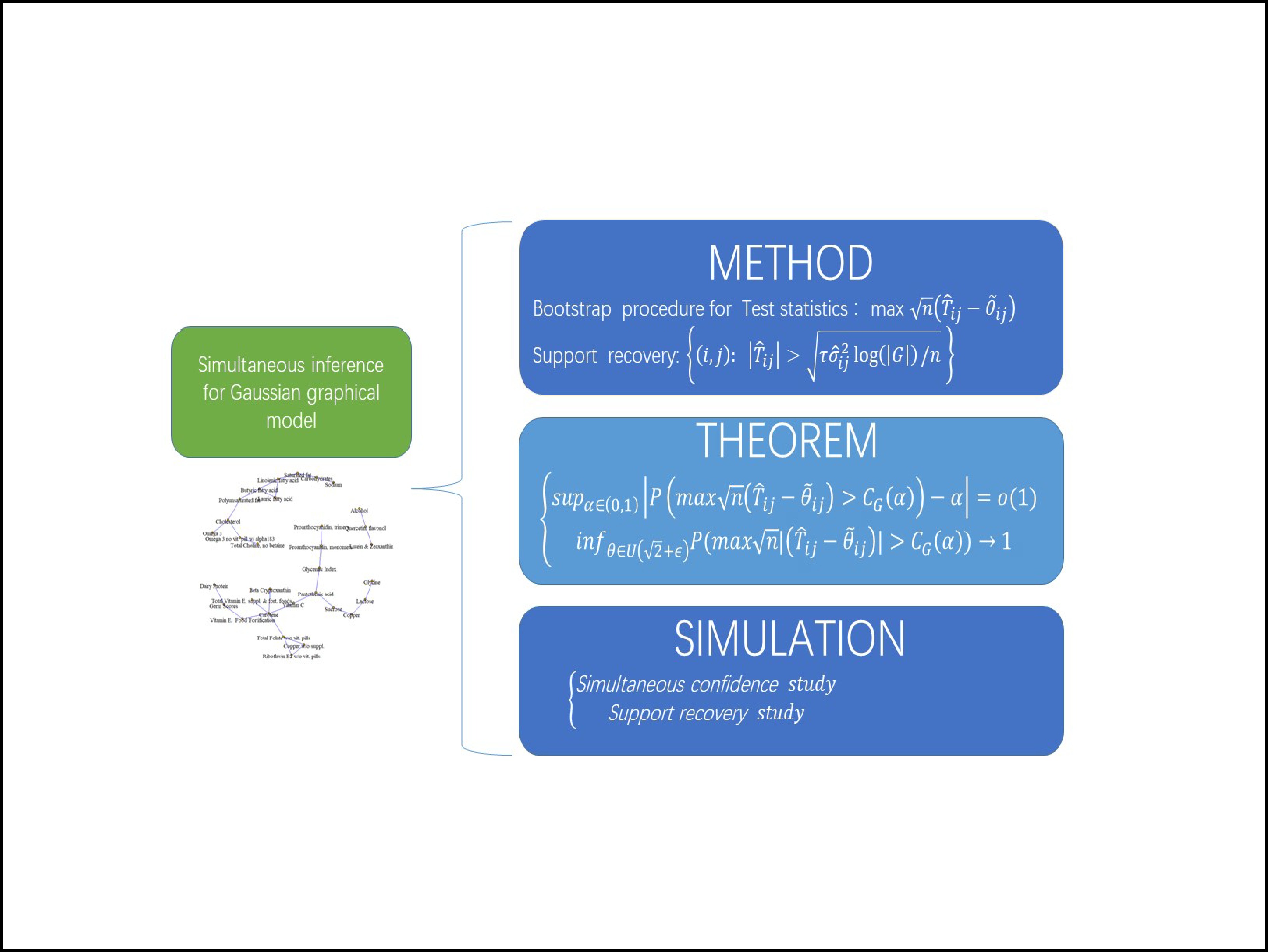
The method, theorem and simulation study of the simultaneous inference for a high-dimensional precision matrix.
| [1] |
Lauritzen S L. Graphical Models. London: Clarendon Press, 1996.
|
| [2] |
Belilovsky E, Varoquaux G, Blaschko M B. Testing for differences in Gaussian graphical models: Applications to brain connectivity. https://arxiv.org/abs/1512.08643.
|
| [3] |
Yuan M, Lin Y. Model selection and estimation in the Gaussian graphical model. Biometrika, 2007, 94: 19–35. DOI: 10.1093/biomet/asm018
|
| [4] |
Fan J Q, Yang F, Wu Y. Network exploration via the adaptive lasso and scad penalties. The Annals of Applied Statistics, 2009, 3 (2): 521–541. DOI: 10.1214/08-AOAS215SUPP
|
| [5] |
Friedman J, Hastie T, Tibshirani R. Sparse inverse covariance estimation with the graphical Lasso. Biostatistics, 2007, 9: 432–441. DOI: 10.1093/biostatistics/kxm045
|
| [6] |
Meinshausen N, Bühlmann P. High-dimensional graphs and variable selection with the lasso. The Annals of Statistics, 2006, 34: 1436–1462. DOI: 10.1214/009053606000000281
|
| [7] |
Cai T T, Liu W, Zhou H H. Estimating sparse precision matrix: Optimal rates of convergence and adaptive estimation. The Annals of Statistics, 2016, 44: 455–488. DOI: 10.1214/13-AOS1171
|
| [8] |
Peng J, Wang P, Zhou N, et al. Partial correlation estimation by joint sparse regression models. Journal of the American Statistical Association, 2009, 104: 735–746. DOI: 10.1198/jasa.2009.0126
|
| [9] |
Fan Y, Lv J. Innovated scalable efficient estimation in ultra-large Gaussian graphical models. The Annals of Statistics, 2016, 44: 2098–2126. DOI: 10.1214/15-AOS1416
|
| [10] |
Zhang C H, Zhang S S. Confidence intervals for low dimensional parameters in high dimensional linear models. Journal of the Royal Statistical Society, 2014, 76: 217–242. DOI: 10.1111/rssb.12026
|
| [11] |
Jankov J, van de Geer S. Confidence intervals for high-dimensional inverse covariance estimation. Electronic Journal of Statistics, 2015, 9: 1205–1229. DOI: 10.1214/15-EJS1031
|
| [12] |
Jankov J, van de Geer S. Honest confidence regions and optimality in high-dimensional precision matrix estimation. Test, 2017, 26: 143–162. DOI: 10.1007/s11749-016-0503-5
|
| [13] |
Zhou J, Zheng Z, Zhou H, et al. Innovated scalable efficient inference for ultra-large graphical models. Statistics and Probability Letters, 2021, 173: 109085. DOI: 10.1016/j.spl.2021.109085
|
| [14] |
Zhang X, Cheng G. Simultaneous inference for high-dimensional linear models. Journal of the American Statistical Association, 2017, 112: 757–768. DOI: 10.1080/01621459.2016.1166114
|
| [15] |
Chernozhukov V, Chetverikov D, Kato K. Gaussian approximations and multiplier bootstrap for maxima of sums of high-dimensional random vectors. The Annals of Statistics, 2013, 41: 2786–2819. DOI: 10.1214/13-AOS1161
|
| [16] |
Cai T T, Liu W, Xia Y. Two-sample test of high dimensional means under dependence. Journal of the Royal Statistical Society, Series B(Statistical Methodology), 2014, 76: 349–372. DOI: 10.1111/rssb.12034
|

ISSN 0253-2778
CN 34-1054/N
Copyright © Editorial Office of JUSTC, All Rights Reserved. 皖ICP备05002528号
Supported by: Beijing Renhe Information Technology Co., Ltd. 
| Category | Value |
| Ambient temperature (℃) | 18.0 |
| Environmental pressure (MPa) | 0.1 |
| Inlet pressure (MPa) | 0.1 |
| Working fluid flow (L·h−1) | 53.0 |
| Inlet temperature (℃) | 15.0 |
| Nozzle diameter (mm) | 0.3 |
| Types of additives | SDS, N-octanol, Tween20 |
| Additive concentration (ppm) | 100 / 200 / 300 / 400 |
 DownLoad:
CSV
DownLoad:
CSV
| Parameters | Measurement error |
| Temperature (℃) | ± 0.5 |
| Pressure (MPa) | ± 0.002 |
| Voltage (V) | ± 0.5 |
| Flow (L·h−1) | ± 0.1 |
| Current (mA) | ± 1 |
| Length (mm) | ± 0.1 |
DownLoad:
CSV
| Parameters | Uncertainty |
| q″ (W·cm−2) | ± 1.4% |
| h (W·cm−2·K−1) | ± 1.5% |
| Nu | ± 2.5% |
| Re | ± 0.7% |
| Pr | ± 2.5% |
| We | ± 0.2% |
| ε | ± 0.8% |
DownLoad:
CSV
| Additives | coefficient | |||||
| A | B | C | D | E | F | |
| SDS | −1.815 | 1.167 | 0.089 | 0.150 | −4.891 | −0.253 |
| N-octanol | 2259 | 2.057 | 0.061 | 0.788 | −1.000 | 1.182 |
| Tween20 | 0.295 | 1.198 | −0.382 | 2.106 | 0.387 | 0.218 |
DownLoad:
CSV























