| [1] |
Chantrill L A, Nagrial A M, Watson C, et al. Precision medicine for advanced pancreas cancer: The individualized molecular pancreatic cancer therapy (IMPaCT) trial. Clinical Cancer Research, 2015, 21 (9): 2029–2037. doi: 10.1158/1078-0432.CCR-15-0426
|
| [2] |
Sun W, Wang P, Yin D, et al. Causal inference via sparse additive models with application to online advertising. Proceedings of the AAAI Conference on Artificial Intelligence, 2015, 29 (1): 297–303. doi: 10.1609/aaai.v29i1.9156
|
| [3] |
Athey S, Imbens G W. The state of applied econometrics: Causality and policy evaluation. Journal of Economic Perspectives, 2017, 31 (2): 3–32. doi: 10.1257/jep.31.2.3
|
| [4] |
Wager S, Athey S. Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association, 2018, 113 (523): 1228–1242. doi: 10.1080/01621459.2017.1319839
|
| [5] |
Richard Hahn P, Murray J S, Carvalho C M. Bayesian regression tree models for causal inference: Regularization, confounding, and heterogeneous effects (with Discussion). Bayesian Analysis, 2020, 15 (3): 965–1056. doi: 10.1214/19-BA1195
|
| [6] |
Stuart E A. Matching methods for causal inference: A review and a look forward. Statistical Science, 2010, 25 (1): 1–21. doi: 10.1214/09-STS313
|
| [7] |
Gao Z, Hastie T, Tibshirani R. Assessment of heterogeneous treatment effect estimation accuracy via matching. Statistics in Medicine, 2021, 40 (17): 3990–4013. doi: 10.1002/sim.9010
|
| [8] |
Long M, Sun L, Li Q. k-Resolution sequential randomization procedure to improve covariates balance in a randomized experiment. Statistics in Medicine, 2021, 40 (25): 5534–5546. doi: 10.1002/sim.9139
|
| [9] |
Künzel S R, Sekhon J S, Bickel P J, et al. Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the National Academy of Sciences, 2019, 116 (10): 4156–4165. doi: 10.1073/pnas.1804597116
|
| [10] |
Curth A, van der Schaar M. Nonparametric estimation of heterogeneous treatment effects: From theory to learning algorithms. In: Proceedings of the 24th International Conference on Artificial Intelligence and Statistics. San Diego, CA: PMLR, 2021: 1810−1818.
|
| [11] |
Nie X, Wager S. Quasi-oracle estimation of heterogeneous treatment effects. Biometrika, 2021, 108 (2): 299–319. doi: 10.1093/biomet/asaa076
|
| [12] |
Zhang B, Small D S, Lasater K B, et al. Matching one sample according to two criteria in observational studies. Journal of the American Statistical Association, 2023, 118: 1140–1151. doi: 10.1080/01621459.2021.1981337
|
| [13] |
Gao Z, Hastie T, Tibshirani R. Assessment of heterogeneous treatment effect estimation accuracy via matching. Statistics in Medicine, 2021, 40 (17): 3990–4013. doi: 10.1002/sim.9010
|
| [14] |
Iacus S M, King G, Porro G. Causal inference without balance checking: Coarsened exact matching. Political Analysis, 2012, 20: 1–24. doi: 10.1093/pan/mpr013
|
| [15] |
Rubin D B. Matching to remove bias in observational studies. Biometrics, 1973, 29 (1): 159–183. doi: 10.2307/2529684
|
| [16] |
Rosenbaum P R, Rubin D B. The central role of the propensity score in observational studies for causal effects. Biometrika, 1983, 70 (1): 41–55. doi: 10.2307/2335942
|
| [17] |
Rubin D B. Using propensity scores to help design observational studies: Application to the tobacco litigation. Health Services and Outcomes Research Methodology, 2001, 2 (3): 169–188. doi: 10.1023/A:1020363010465
|
| [18] |
Hansen B B. The prognostic analogue of the propensity score. Biometrika, 2008, 95 (2): 481–488. doi: 10.1093/biomet/asn004
|
| [19] |
Leacy F P, Stuart E A. On the joint use of propensity and prognostic scores in estimation of the average treatment effect on the treated: A simulation study. Statistics in Medicine, 2014, 33 (20): 3488–3508. doi: 10.1002/sim.6030
|
| [20] |
Antonelli J, Cefalu M, Palmer N, et al. Doubly robust matching estimators for high dimensional confounding adjustment. Biometrics, 2018, 74 (4): 1171–1179. doi: 10.1111/biom.12887
|
| [21] |
Rosenbaum P R, Rubin D B. Reducing bias in observational studies using subclassification on the propensity score. Journal of the American Statistical Association, 1984, 79 (387): 516–524. doi: 10.2307/2288398
|
| [22] |
Wooldridge J M. Should instrumental variables be used as matching variables? Research in Economics, 2016, 70 (2): 232–237. doi: 10.1016/j.rie.2016.01.001
|
| [23] |
Rosenbaum P R. Optimal matching for observational studies. Journal of the American Statistical Association, 1989, 84 (408): 1024–1032. doi: 10.2307/2290079
|
| [24] |
Zubizarreta J, Keele L. Optimal multilevel matching in clustered observational studies: A case study of the effectiveness of private schools under a large-scale voucher system. Journal of the American Statistical Association, 2017, 112 (518): 547–560. doi: 10.1080/01621459.2016.1240683
|
| [25] |
Pimentel S D, Kelz R R. Optimal tradeoffs in matched designs comparing US-trained and internationally trained surgeons. Journal of the American Statistical Association, 2022, 115 (532): 1675–1688. doi: 10.1080/01621459.2020.1720693
|
| [26] |
Yu R, Rosenbaum P R. Directional penalties for optimal matching in observational studies. Biometrics, 2019, 75 (4): 1380–1390. doi: 10.1111/biom.13098
|
| [27] |
Morucci M, Orlandi V, Roy S, et al. Adaptive hyperbox matching for interpretable individualized treatment effect estimation. In: Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI). Toronto, Canada: PMLR, 2020: 1089–1098.
|
| [28] |
Hansen B B, Klopfer S O. Optimal full matching and related designs via network flows. Journal of Computational and Graphical Statistics, 2006, 15 (3): 609–627. doi: 10.1198/106186006X137047
|
| [29] |
Pimentel S D, Kelz R R, Silber J H, et al. Large, sparse optimal matching with refined covariate balance in an observational study of the health outcomes produced by new surgeons. Journal of the American Statistical Association, 2015, 110 (510): 515–527. doi: 10.1080/01621459.2014.997879
|
| [30] |
Rubin D B. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 1974, 66 (5): 688–701. doi: 10.1037/h0037350
|
| [31] |
Robinson P M. Root-N-consistent semiparametric regression. Econometrica, 1988, 56: 931–954. doi: 0012-9682(198807)56:4<931:RSR>2.0.CO;2-3
|
| [32] |
Glazerman S, Levy D M, Myers D. Nonexperimental versus experimental estimates of earnings impacts. The Annals of the American Academy of Political and Social Science, 2003, 589 (1): 63–93. doi: 10.1177/0002716203254879
|
| [33] |
Pearl J. On a class of bias-amplifying variables that endanger effect estimates. In: Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence. Arlington, VA: AUAI Press, 2010: 417−424.
|
| [34] |
Chen Y L. The minimal average cost flow problem. European Journal of Operational Research, 1995, 81 (3): 561–570. doi: 10.1016/0377-2217(93)E0348-2
|
| [35] |
Brito M R, Chávez E L, Quiroz A J, et al. Connectivity of the mutual k-nearest-neighbor graph in clustering and outlier detection. Statistics & Probability Letters, 1997, 35 (1): 33–42. doi: 10.1016/S0167-7152(96)00213-1
|
| [36] |
Korte B, Vygen J. Combinatorial Optimization: Theory and Algorithms. Berlin: Springer, 2011.
|
| [37] |
Ye S S, Chen Y, Padilla O H M. Non-parametric interpretable score based estimation of heterogeneous treatment effects. arXiv.2110.02401, 2021.
|
| [38] |
Chipman H A, George E I, McCulloch R E. BART: Bayesian additive regression trees. The Annals of Applied Statistics, 2010, 4: 266–298. doi: 10.1214/09-AOAS285
|
| [39] |
Brand J E, Xu J, Koch B, et al. Uncovering sociological effect heterogeneity using machine learning. arXiv: 1909.09138, 2019.
|
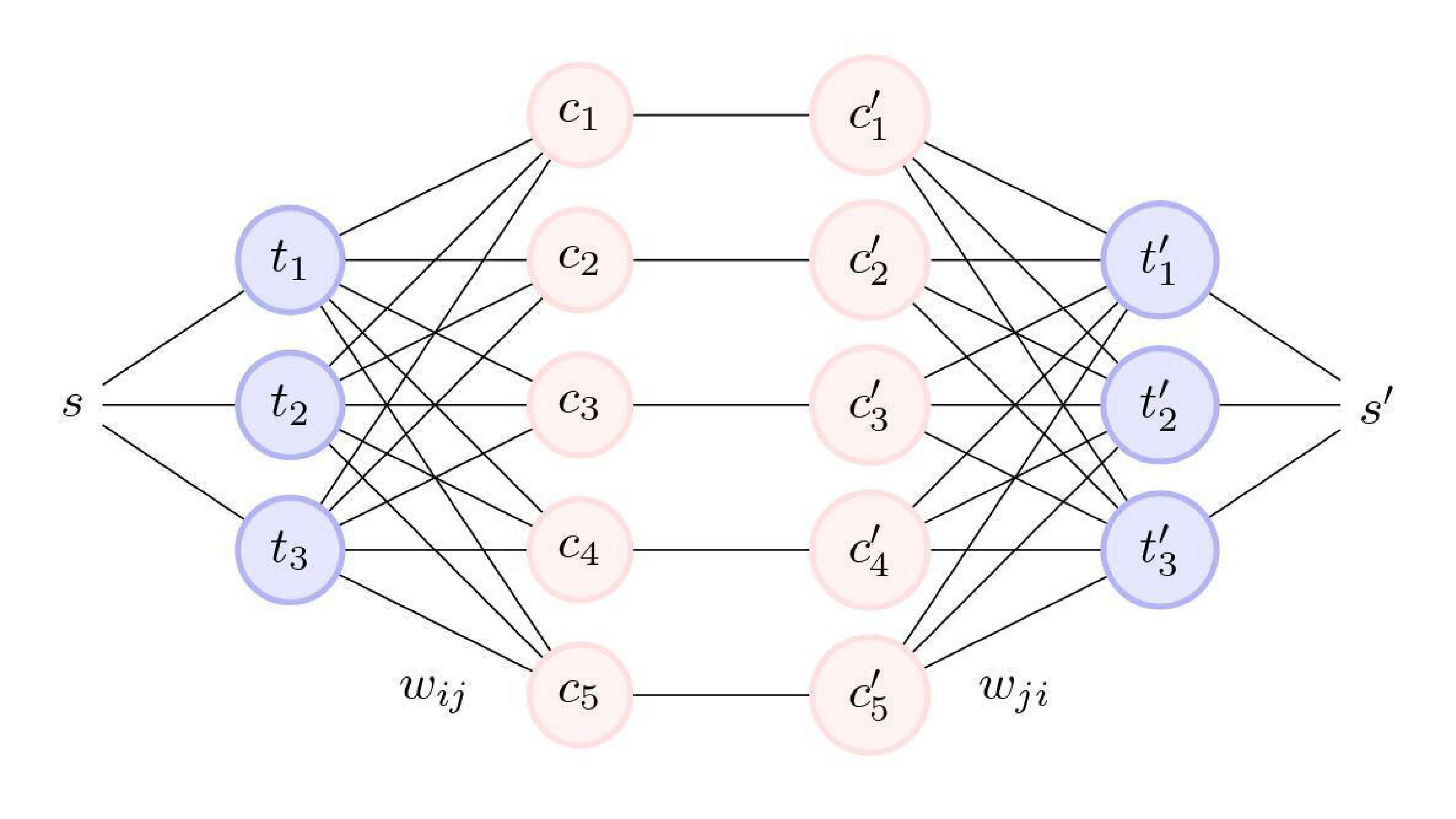
Figure 1. Tripartite network structure.
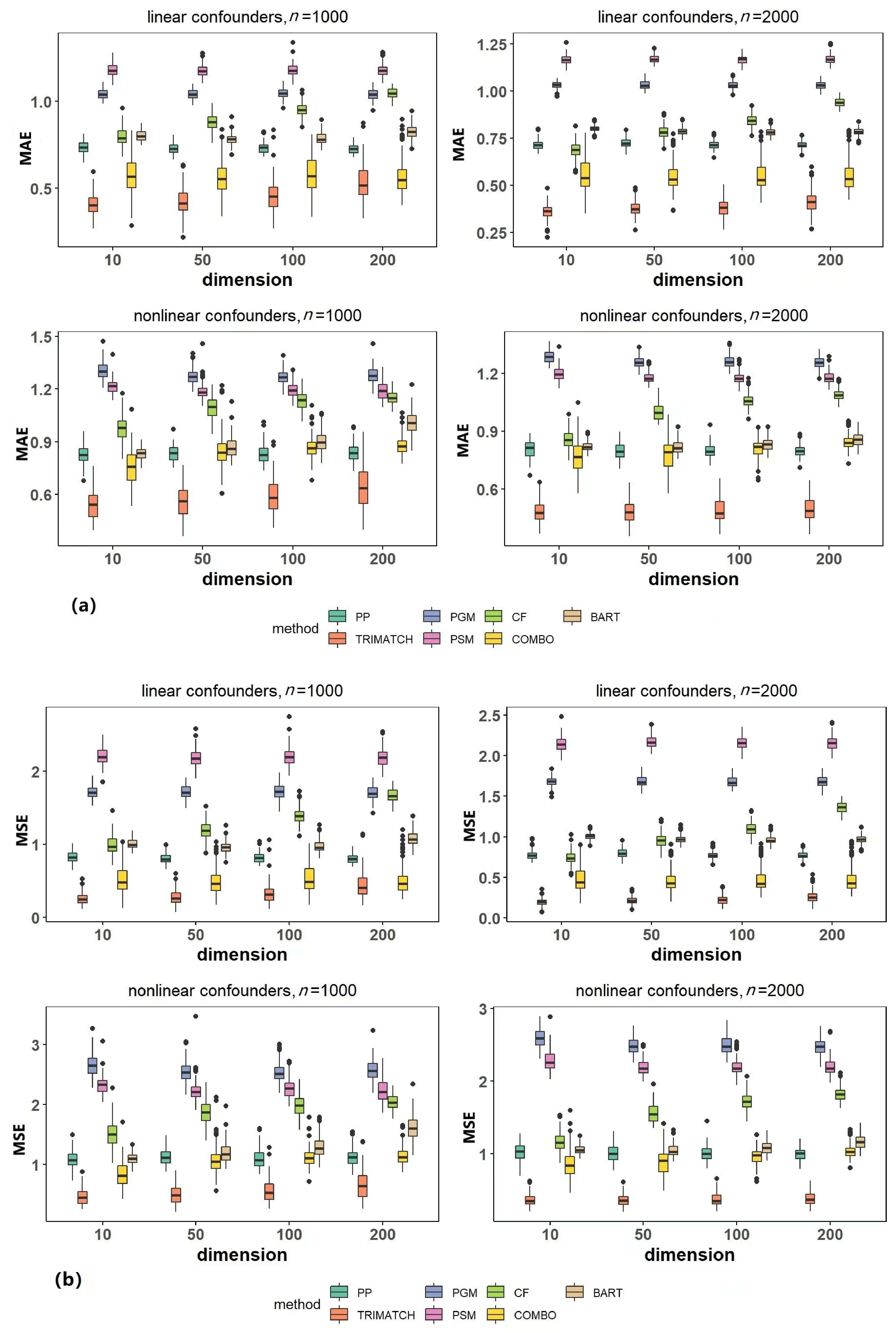
Figure 2. Comparison between different methods. (a) Mean absolute errors of 100 simulations forvarious methods. (b) Mean squared errors of 100 simulations for various methods
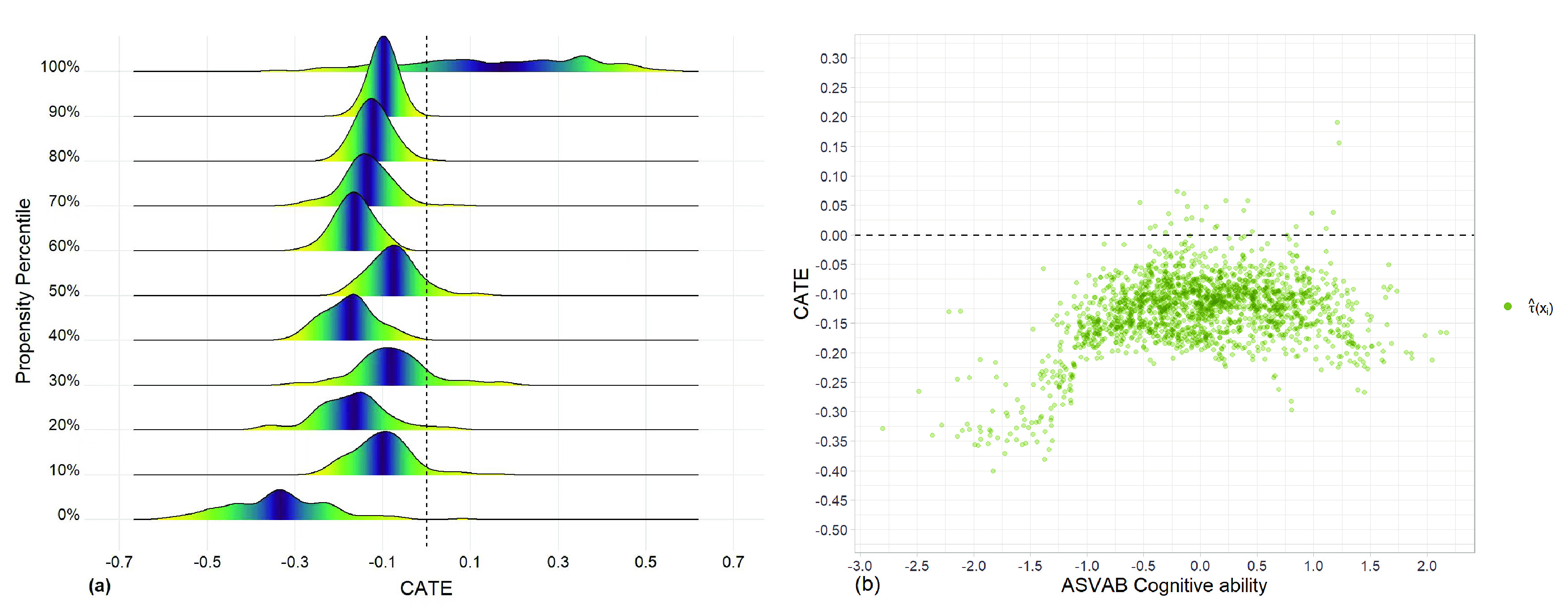
Figure 3. (a) The graph displays the distribution of estimated heterogeneous treatment effects corresponding to the approximated propensity score percentiles. (b) Scatter plots of estimated treatment effect (averaged over the 100 iterations) against ASVAB cognitive ability.
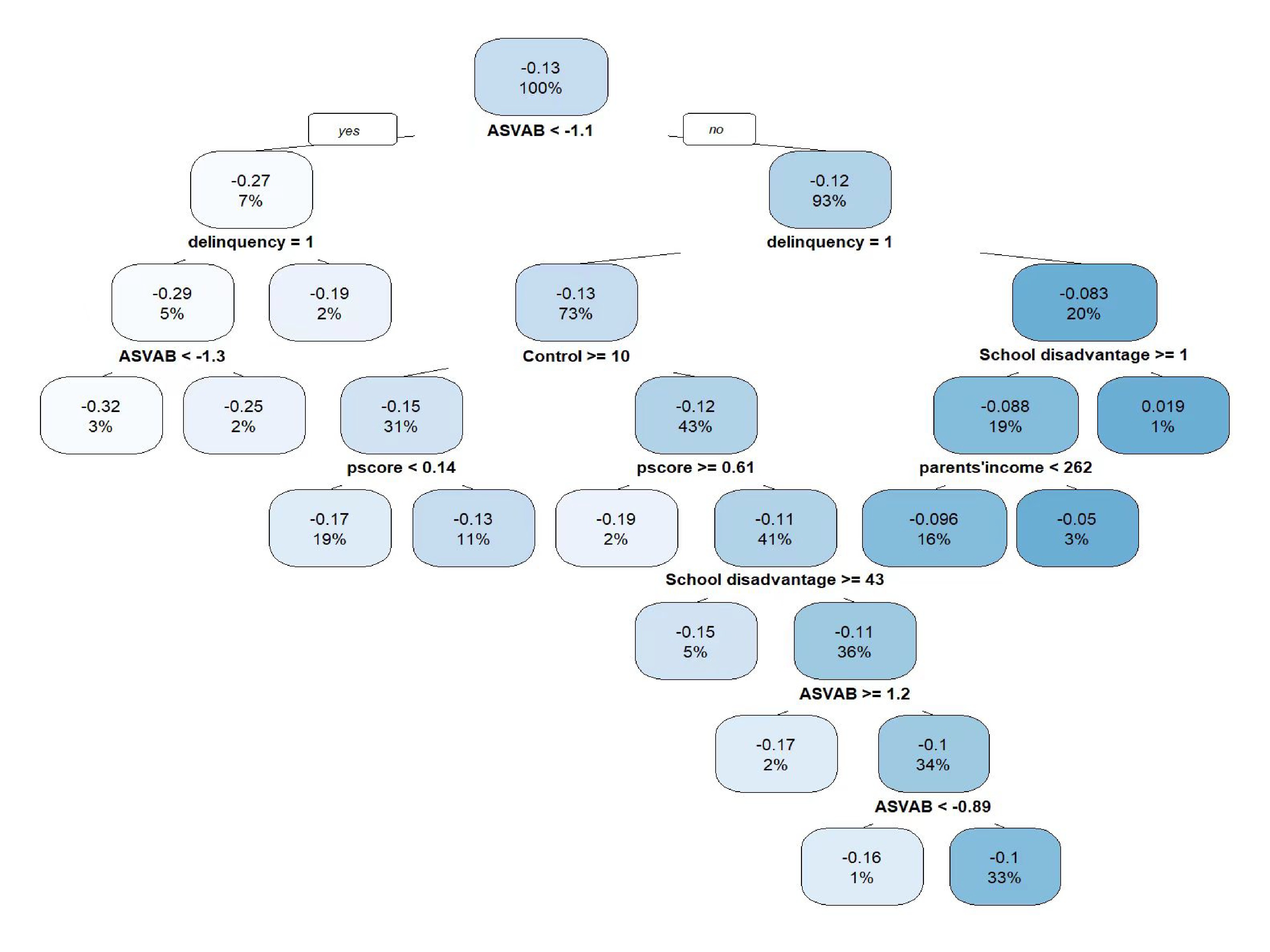
Figure 4. Prediction model of heterogeneous treatment effects
| [1] |
Chantrill L A, Nagrial A M, Watson C, et al. Precision medicine for advanced pancreas cancer: The individualized molecular pancreatic cancer therapy (IMPaCT) trial. Clinical Cancer Research, 2015, 21 (9): 2029–2037. doi: 10.1158/1078-0432.CCR-15-0426
|
| [2] |
Sun W, Wang P, Yin D, et al. Causal inference via sparse additive models with application to online advertising. Proceedings of the AAAI Conference on Artificial Intelligence, 2015, 29 (1): 297–303. doi: 10.1609/aaai.v29i1.9156
|
| [3] |
Athey S, Imbens G W. The state of applied econometrics: Causality and policy evaluation. Journal of Economic Perspectives, 2017, 31 (2): 3–32. doi: 10.1257/jep.31.2.3
|
| [4] |
Wager S, Athey S. Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association, 2018, 113 (523): 1228–1242. doi: 10.1080/01621459.2017.1319839
|
| [5] |
Richard Hahn P, Murray J S, Carvalho C M. Bayesian regression tree models for causal inference: Regularization, confounding, and heterogeneous effects (with Discussion). Bayesian Analysis, 2020, 15 (3): 965–1056. doi: 10.1214/19-BA1195
|
| [6] |
Stuart E A. Matching methods for causal inference: A review and a look forward. Statistical Science, 2010, 25 (1): 1–21. doi: 10.1214/09-STS313
|
| [7] |
Gao Z, Hastie T, Tibshirani R. Assessment of heterogeneous treatment effect estimation accuracy via matching. Statistics in Medicine, 2021, 40 (17): 3990–4013. doi: 10.1002/sim.9010
|
| [8] |
Long M, Sun L, Li Q. k-Resolution sequential randomization procedure to improve covariates balance in a randomized experiment. Statistics in Medicine, 2021, 40 (25): 5534–5546. doi: 10.1002/sim.9139
|
| [9] |
Künzel S R, Sekhon J S, Bickel P J, et al. Metalearners for estimating heterogeneous treatment effects using machine learning. Proceedings of the National Academy of Sciences, 2019, 116 (10): 4156–4165. doi: 10.1073/pnas.1804597116
|
| [10] |
Curth A, van der Schaar M. Nonparametric estimation of heterogeneous treatment effects: From theory to learning algorithms. In: Proceedings of the 24th International Conference on Artificial Intelligence and Statistics. San Diego, CA: PMLR, 2021: 1810−1818.
|
| [11] |
Nie X, Wager S. Quasi-oracle estimation of heterogeneous treatment effects. Biometrika, 2021, 108 (2): 299–319. doi: 10.1093/biomet/asaa076
|
| [12] |
Zhang B, Small D S, Lasater K B, et al. Matching one sample according to two criteria in observational studies. Journal of the American Statistical Association, 2023, 118: 1140–1151. doi: 10.1080/01621459.2021.1981337
|
| [13] |
Gao Z, Hastie T, Tibshirani R. Assessment of heterogeneous treatment effect estimation accuracy via matching. Statistics in Medicine, 2021, 40 (17): 3990–4013. doi: 10.1002/sim.9010
|
| [14] |
Iacus S M, King G, Porro G. Causal inference without balance checking: Coarsened exact matching. Political Analysis, 2012, 20: 1–24. doi: 10.1093/pan/mpr013
|
| [15] |
Rubin D B. Matching to remove bias in observational studies. Biometrics, 1973, 29 (1): 159–183. doi: 10.2307/2529684
|
| [16] |
Rosenbaum P R, Rubin D B. The central role of the propensity score in observational studies for causal effects. Biometrika, 1983, 70 (1): 41–55. doi: 10.2307/2335942
|
| [17] |
Rubin D B. Using propensity scores to help design observational studies: Application to the tobacco litigation. Health Services and Outcomes Research Methodology, 2001, 2 (3): 169–188. doi: 10.1023/A:1020363010465
|
| [18] |
Hansen B B. The prognostic analogue of the propensity score. Biometrika, 2008, 95 (2): 481–488. doi: 10.1093/biomet/asn004
|
| [19] |
Leacy F P, Stuart E A. On the joint use of propensity and prognostic scores in estimation of the average treatment effect on the treated: A simulation study. Statistics in Medicine, 2014, 33 (20): 3488–3508. doi: 10.1002/sim.6030
|
| [20] |
Antonelli J, Cefalu M, Palmer N, et al. Doubly robust matching estimators for high dimensional confounding adjustment. Biometrics, 2018, 74 (4): 1171–1179. doi: 10.1111/biom.12887
|
| [21] |
Rosenbaum P R, Rubin D B. Reducing bias in observational studies using subclassification on the propensity score. Journal of the American Statistical Association, 1984, 79 (387): 516–524. doi: 10.2307/2288398
|
| [22] |
Wooldridge J M. Should instrumental variables be used as matching variables? Research in Economics, 2016, 70 (2): 232–237. doi: 10.1016/j.rie.2016.01.001
|
| [23] |
Rosenbaum P R. Optimal matching for observational studies. Journal of the American Statistical Association, 1989, 84 (408): 1024–1032. doi: 10.2307/2290079
|
| [24] |
Zubizarreta J, Keele L. Optimal multilevel matching in clustered observational studies: A case study of the effectiveness of private schools under a large-scale voucher system. Journal of the American Statistical Association, 2017, 112 (518): 547–560. doi: 10.1080/01621459.2016.1240683
|
| [25] |
Pimentel S D, Kelz R R. Optimal tradeoffs in matched designs comparing US-trained and internationally trained surgeons. Journal of the American Statistical Association, 2022, 115 (532): 1675–1688. doi: 10.1080/01621459.2020.1720693
|
| [26] |
Yu R, Rosenbaum P R. Directional penalties for optimal matching in observational studies. Biometrics, 2019, 75 (4): 1380–1390. doi: 10.1111/biom.13098
|
| [27] |
Morucci M, Orlandi V, Roy S, et al. Adaptive hyperbox matching for interpretable individualized treatment effect estimation. In: Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI). Toronto, Canada: PMLR, 2020: 1089–1098.
|
| [28] |
Hansen B B, Klopfer S O. Optimal full matching and related designs via network flows. Journal of Computational and Graphical Statistics, 2006, 15 (3): 609–627. doi: 10.1198/106186006X137047
|
| [29] |
Pimentel S D, Kelz R R, Silber J H, et al. Large, sparse optimal matching with refined covariate balance in an observational study of the health outcomes produced by new surgeons. Journal of the American Statistical Association, 2015, 110 (510): 515–527. doi: 10.1080/01621459.2014.997879
|
| [30] |
Rubin D B. Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology, 1974, 66 (5): 688–701. doi: 10.1037/h0037350
|
| [31] |
Robinson P M. Root-N-consistent semiparametric regression. Econometrica, 1988, 56: 931–954. doi: 0012-9682(198807)56:4<931:RSR>2.0.CO;2-3
|
| [32] |
Glazerman S, Levy D M, Myers D. Nonexperimental versus experimental estimates of earnings impacts. The Annals of the American Academy of Political and Social Science, 2003, 589 (1): 63–93. doi: 10.1177/0002716203254879
|
| [33] |
Pearl J. On a class of bias-amplifying variables that endanger effect estimates. In: Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence. Arlington, VA: AUAI Press, 2010: 417−424.
|
| [34] |
Chen Y L. The minimal average cost flow problem. European Journal of Operational Research, 1995, 81 (3): 561–570. doi: 10.1016/0377-2217(93)E0348-2
|
| [35] |
Brito M R, Chávez E L, Quiroz A J, et al. Connectivity of the mutual k-nearest-neighbor graph in clustering and outlier detection. Statistics & Probability Letters, 1997, 35 (1): 33–42. doi: 10.1016/S0167-7152(96)00213-1
|
| [36] |
Korte B, Vygen J. Combinatorial Optimization: Theory and Algorithms. Berlin: Springer, 2011.
|
| [37] |
Ye S S, Chen Y, Padilla O H M. Non-parametric interpretable score based estimation of heterogeneous treatment effects. arXiv.2110.02401, 2021.
|
| [38] |
Chipman H A, George E I, McCulloch R E. BART: Bayesian additive regression trees. The Annals of Applied Statistics, 2010, 4: 266–298. doi: 10.1214/09-AOAS285
|
| [39] |
Brand J E, Xu J, Koch B, et al. Uncovering sociological effect heterogeneity using machine learning. arXiv: 1909.09138, 2019.
|

ISSN 0253-2778
CN 34-1054/N
Copyright © Editorial Office of JUSTC, All Rights Reserved. 皖ICP备05002528号
Supported by:
Beijing Renhe Information Technology Co. Ltd





 DownLoad:
DownLoad: