
Mathematics
Display Method:
2024,
54(3):
0305.
doi: 10.52396/JUSTC-2022-0111
Abstract:
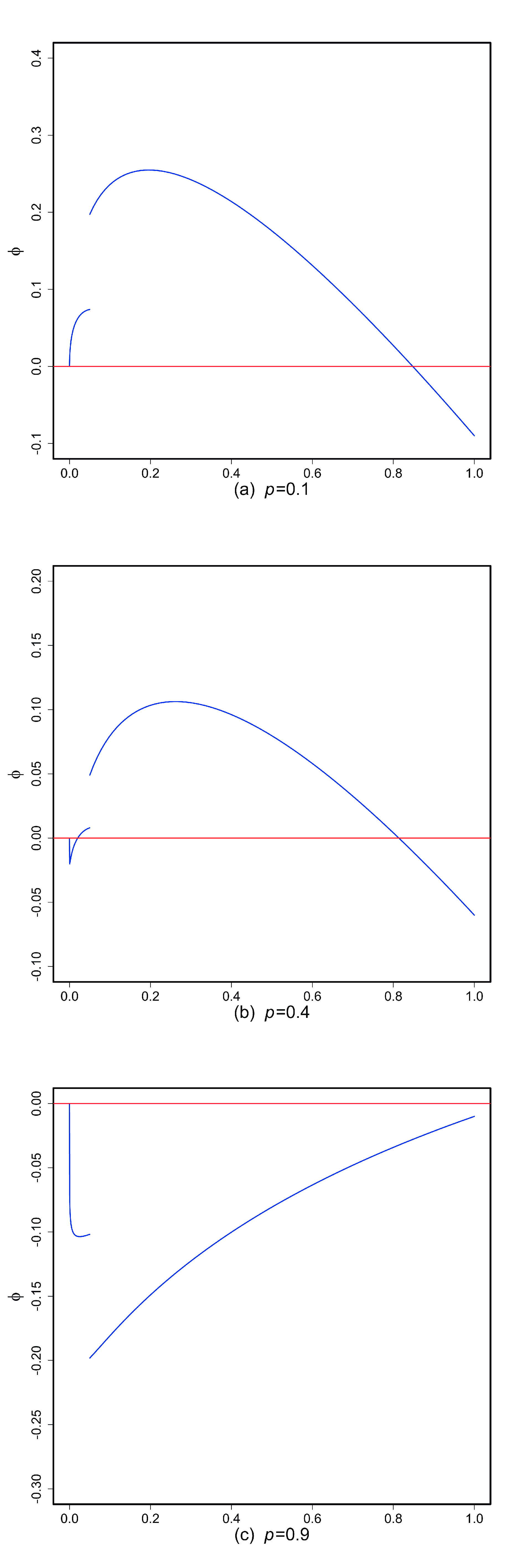
Bowley reinsurance with asymmetric information means that the insurer and reinsurer are both presented with distortion risk measures but there is asymmetric information on the distortion risk measure of the insurer. Motivated by predecessors research, we study Bowley reinsurance with asymmetric information under the reinsurer’s default risk. We call this solution the Bowley solution under default risk. We provide Bowley solutions under default risk in closed form under general assumptions. Finally, some numerical examples are provided to illustrate our main conclusions.
Bowley reinsurance with asymmetric information means that the insurer and reinsurer are both presented with distortion risk measures but there is asymmetric information on the distortion risk measure of the insurer. Motivated by predecessors research, we study Bowley reinsurance with asymmetric information under the reinsurer’s default risk. We call this solution the Bowley solution under default risk. We provide Bowley solutions under default risk in closed form under general assumptions. Finally, some numerical examples are provided to illustrate our main conclusions.
2023,
53(12):
1208.
doi: 10.52396/JUSTC-2023-0019
Abstract:
Galois dual codes are a generalization of Euclidean dual codes and Hermitian dual codes. We show that the\begin{document}$ h $\end{document} ![]()
![]()
\begin{document}$ C_{ {\cal{L}},F}(D,G) $\end{document} ![]()
![]()
\begin{document}$ F/ \mathbb{F}_{p^e} $\end{document} ![]()
![]()
\begin{document}$ C_{\varOmega,F'}(\phi_{h}(D),\phi_{h}(G)) $\end{document} ![]()
![]()
\begin{document}$ F'/ \mathbb{F}_{p^e} $\end{document} ![]()
![]()
\begin{document}$\phi_{h}:F\rightarrow F'$\end{document} ![]()
![]()
\begin{document}$ \phi_{h}(a) = a^{p^{e-h}} $\end{document} ![]()
![]()
\begin{document}$ a\in \mathbb{F}_{p^e} $\end{document} ![]()
![]()
Galois dual codes are a generalization of Euclidean dual codes and Hermitian dual codes. We show that the









2023,
53(11):
1101.
doi: 10.52396/JUSTC-2023-0014
Abstract:
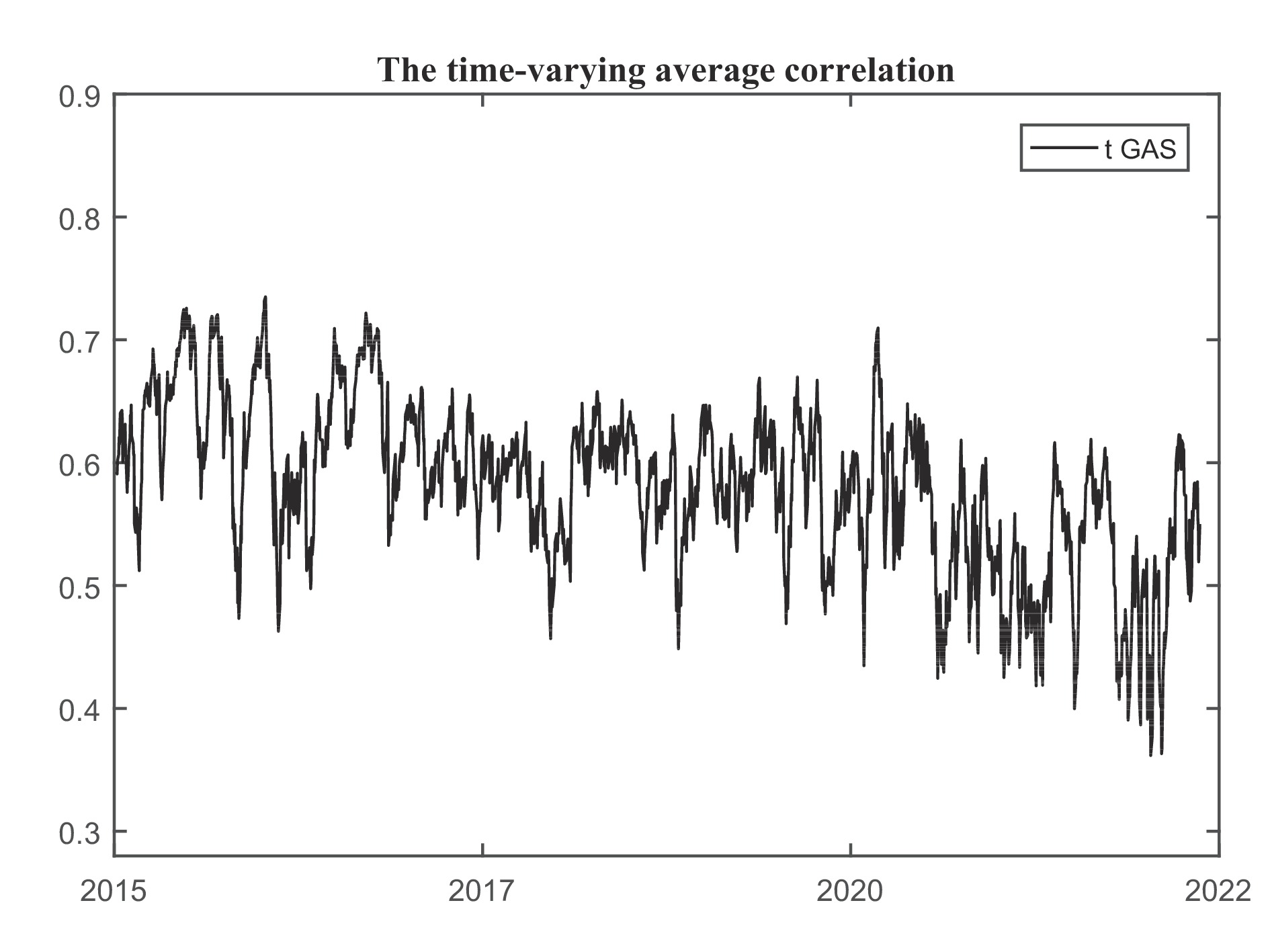
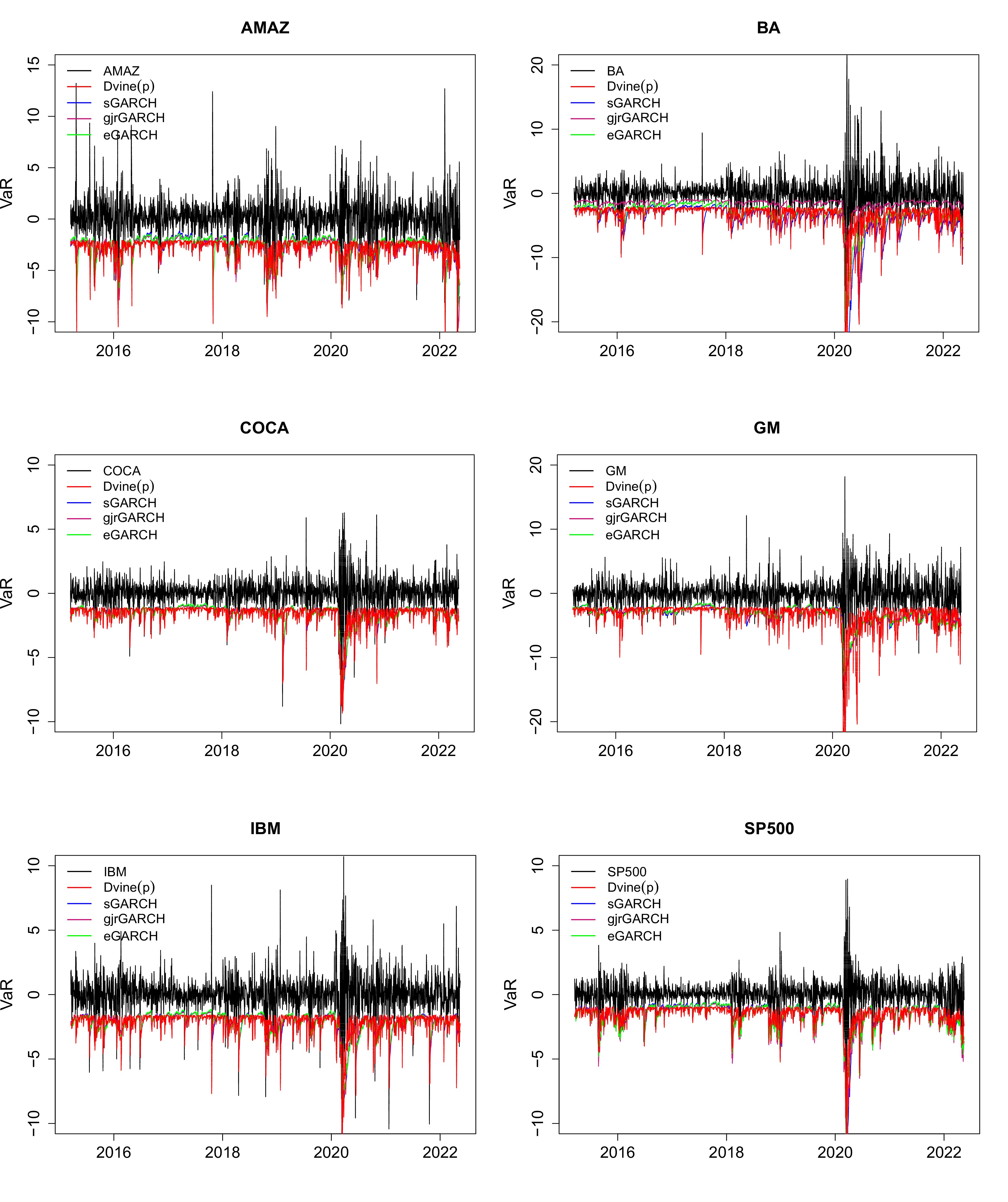
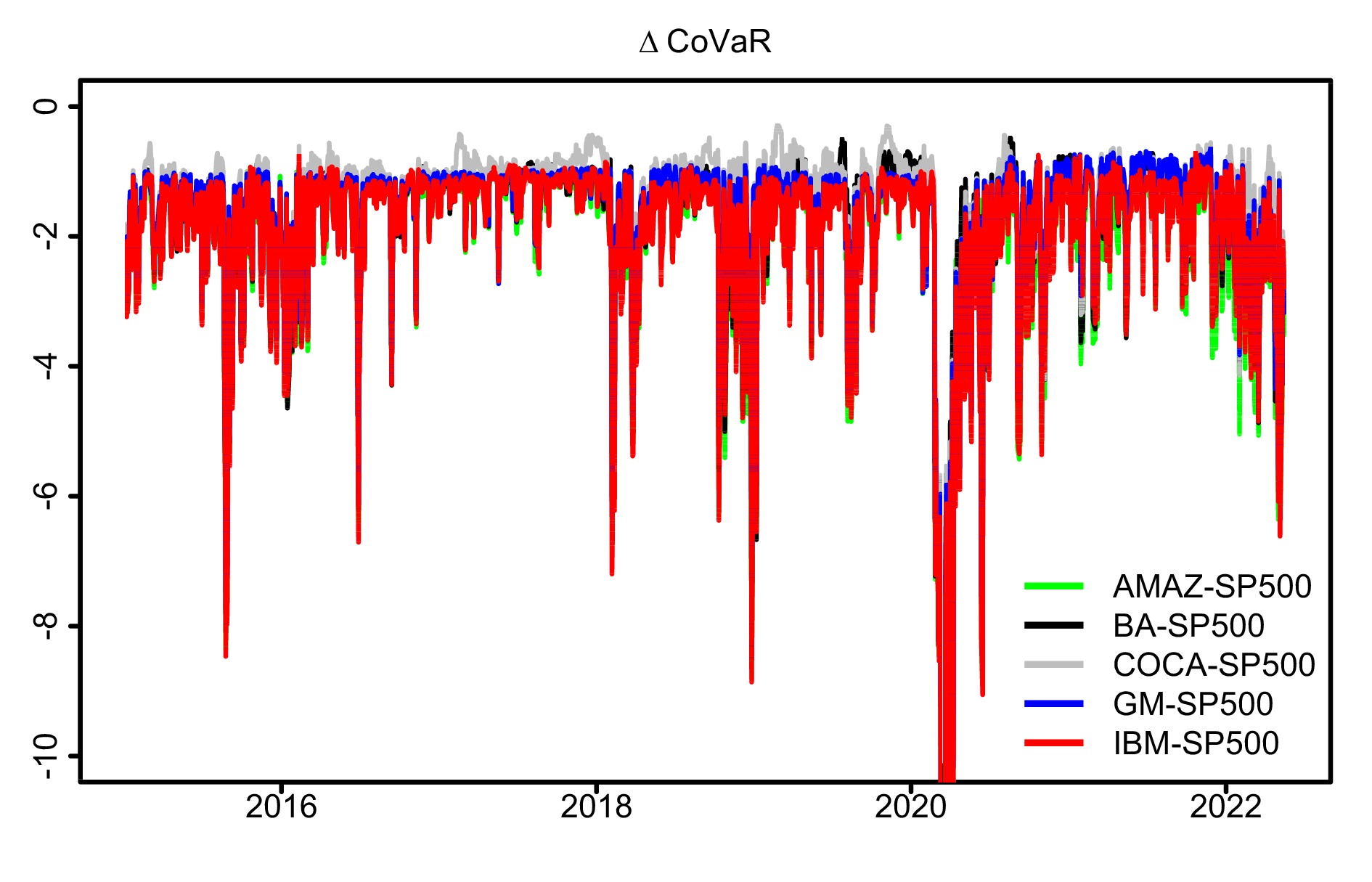
Accurate measurements of the tail risk of financial assets are major interest in financial markets. The main objective of our paper is to measure and forecast the value-at-risk (VaR) and the conditional value-at-risk (CoVaR) of financial assets using a new bivariate time series model. The proposed model can simultaneously capture serial dependence and cross-sectional dependence that exist in bivariate time series to improve the accuracy of estimation and prediction. In the process of model inference, we provide the parameter estimators of our bivariate time series model and give the estimators of VaR and CoVaR via the plug-in principle. We also establish the asymptotic properties of the Dvine model estimators. Real applications for financial stock price show that our model performs well in risk measurement and prediction.
Accurate measurements of the tail risk of financial assets are major interest in financial markets. The main objective of our paper is to measure and forecast the value-at-risk (VaR) and the conditional value-at-risk (CoVaR) of financial assets using a new bivariate time series model. The proposed model can simultaneously capture serial dependence and cross-sectional dependence that exist in bivariate time series to improve the accuracy of estimation and prediction. In the process of model inference, we provide the parameter estimators of our bivariate time series model and give the estimators of VaR and CoVaR via the plug-in principle. We also establish the asymptotic properties of the Dvine model estimators. Real applications for financial stock price show that our model performs well in risk measurement and prediction.

2023,
53(11):
1102.
doi: 10.52396/JUSTC-2022-0054
Abstract:
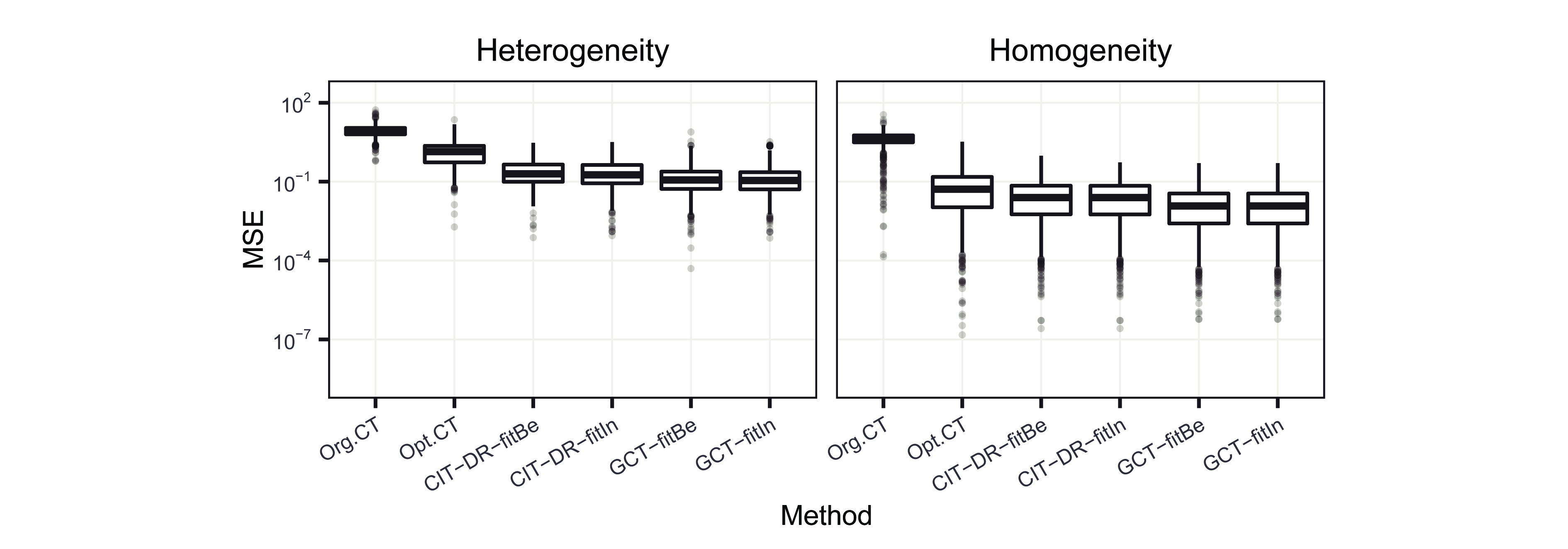
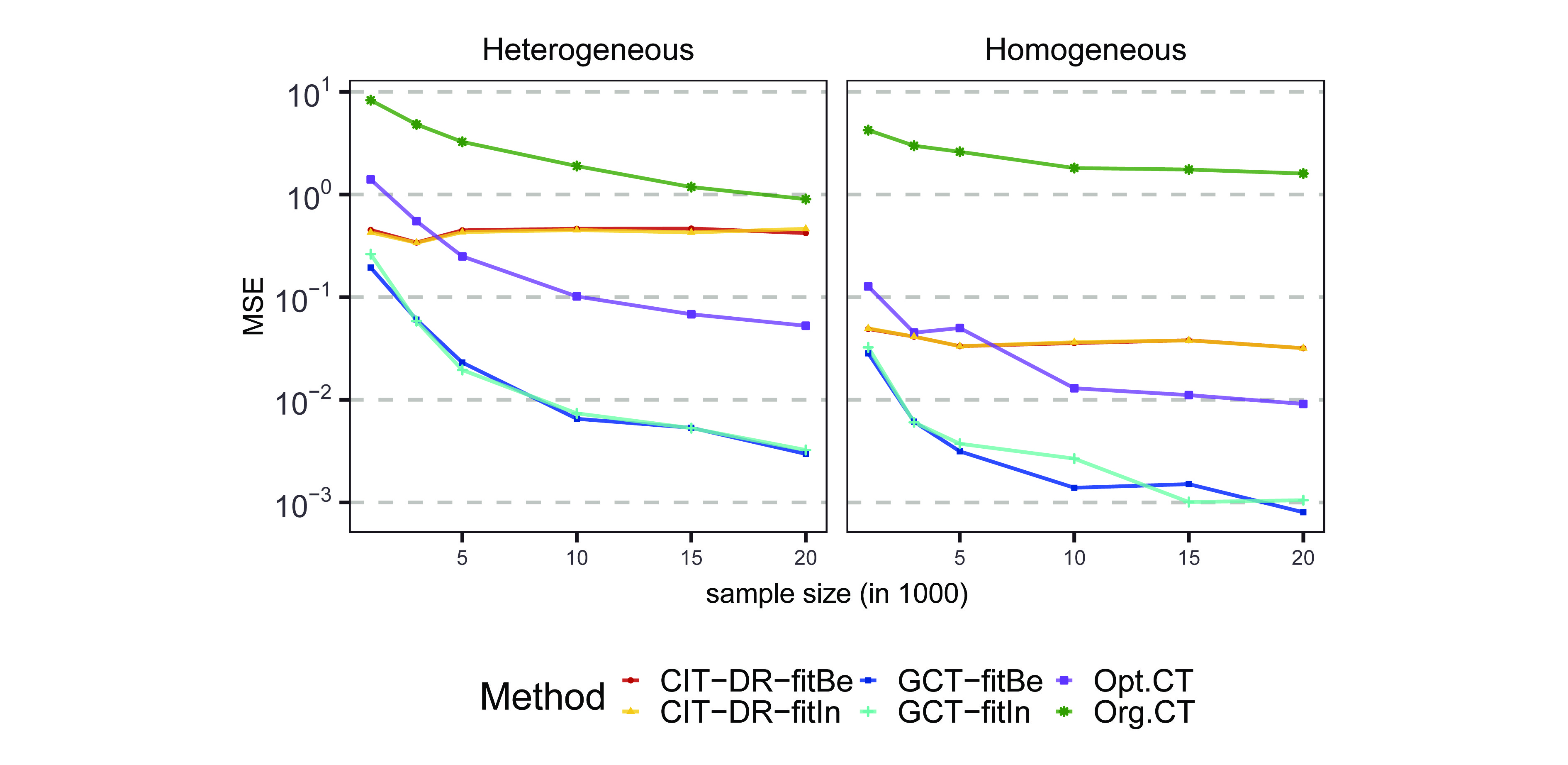
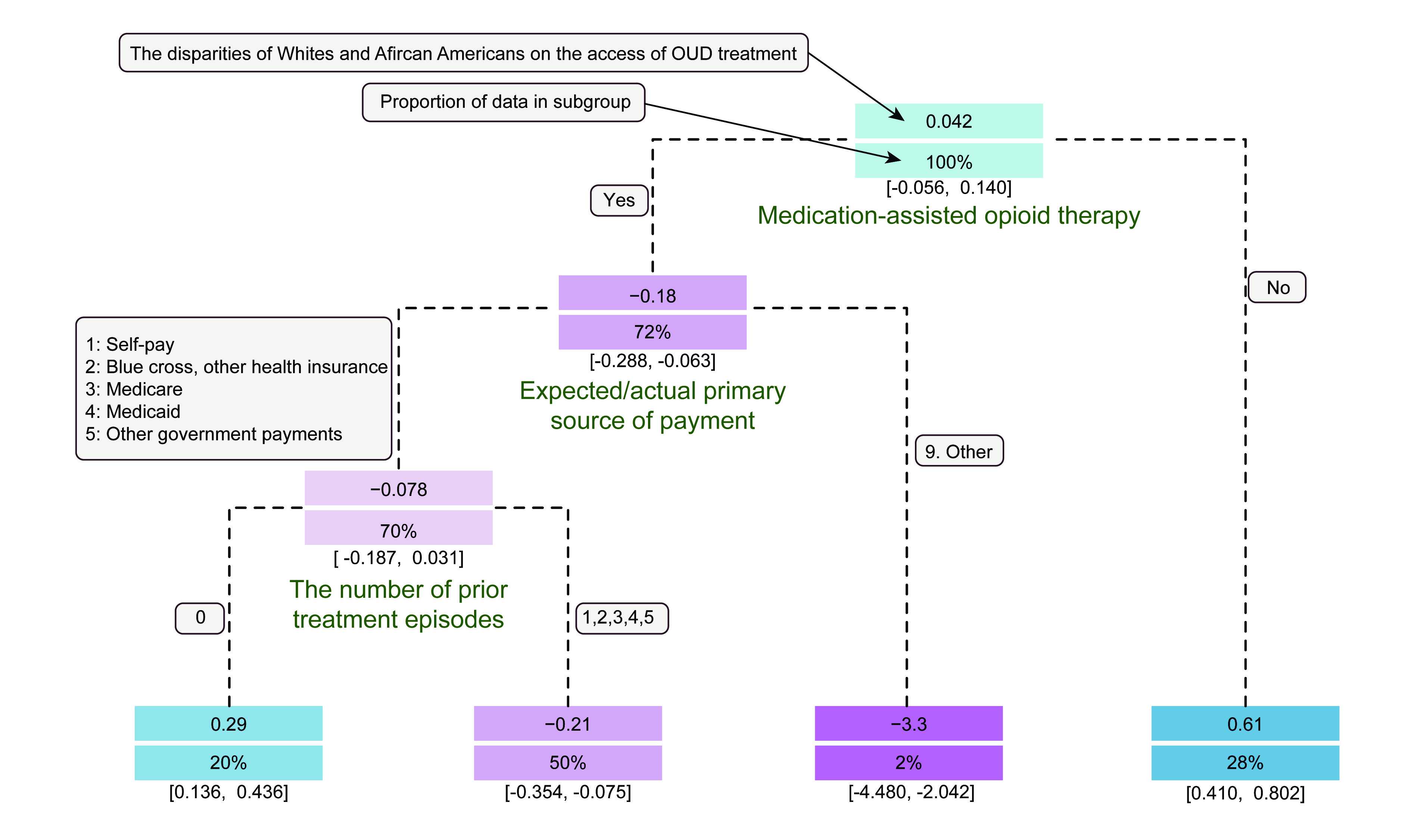
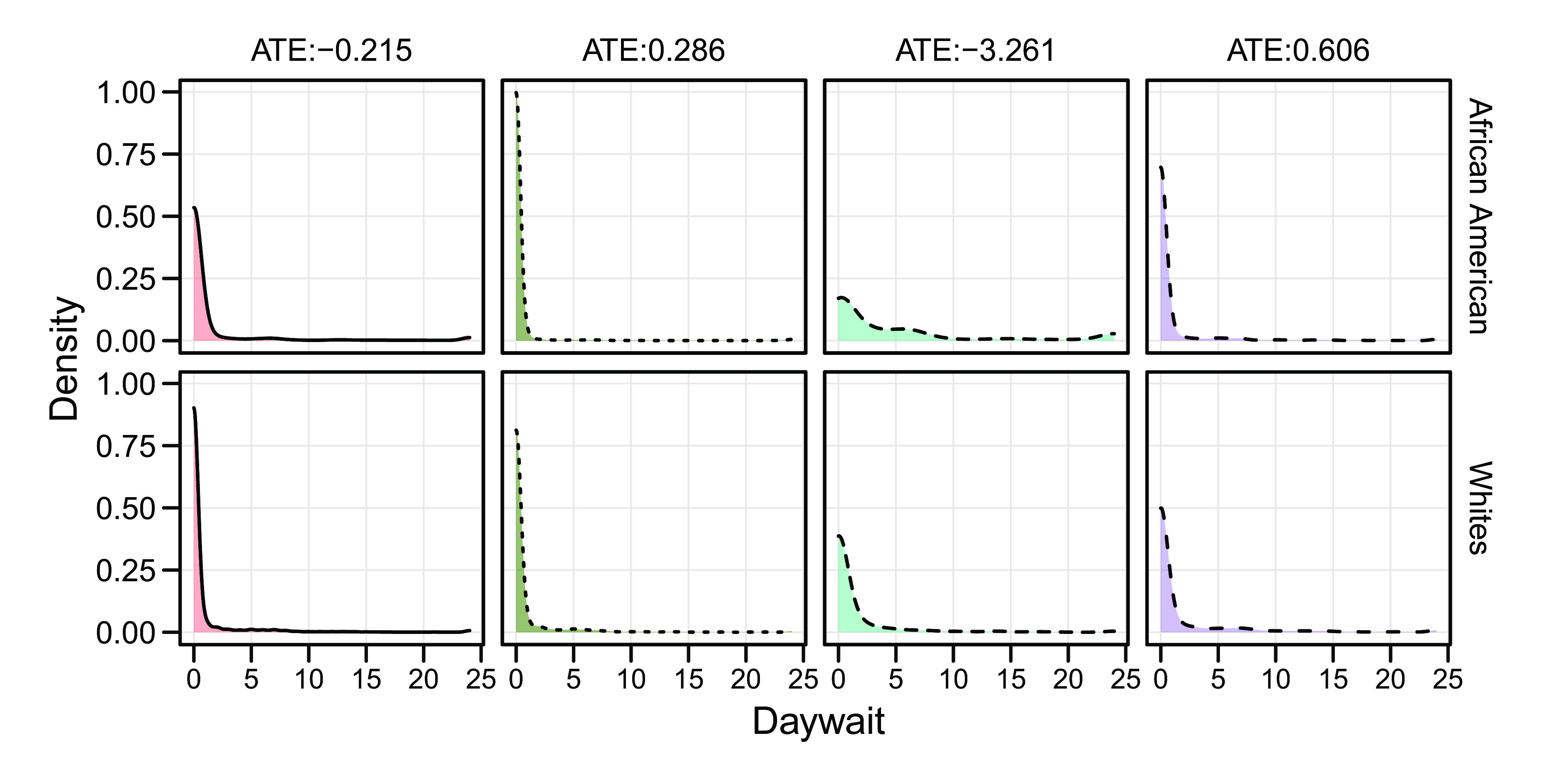
Exploring heterogeneity in causal effects has wide applications in the field of policy evaluation and decision-making. In recent years, researchers have begun employing machine learning methods to study causality, among which the most popular methods generally estimate heterogeneous treatment effects at the individual level. However, we argue that in large sample cases, identifying heterogeneity at the subgroup level is more intuitive and intelligble from a decision-making perspective. In this paper, we provide a tree-based method, called the generic causal tree (GCT), to identify the subgroup-level treatment effects in observational studies. The tree is designed to split by maximizing the disparity of treatment effects between subgroups, embedding a semiparametric framework for the improvement of treatment effect estimation. To accomplish valid statistical inference of the tree-based estimators of treatment effects, we adopt honest estimation to separate tree-building process and inference process. In the simulation, we show that the GCT algorithm has distinct advantages in subgroup identification and gives estimation with higher accuracy compared with the other two benchmark methods. Additionally, we verify the effectiveness of statistical inference by GCT.
Exploring heterogeneity in causal effects has wide applications in the field of policy evaluation and decision-making. In recent years, researchers have begun employing machine learning methods to study causality, among which the most popular methods generally estimate heterogeneous treatment effects at the individual level. However, we argue that in large sample cases, identifying heterogeneity at the subgroup level is more intuitive and intelligble from a decision-making perspective. In this paper, we provide a tree-based method, called the generic causal tree (GCT), to identify the subgroup-level treatment effects in observational studies. The tree is designed to split by maximizing the disparity of treatment effects between subgroups, embedding a semiparametric framework for the improvement of treatment effect estimation. To accomplish valid statistical inference of the tree-based estimators of treatment effects, we adopt honest estimation to separate tree-building process and inference process. In the simulation, we show that the GCT algorithm has distinct advantages in subgroup identification and gives estimation with higher accuracy compared with the other two benchmark methods. Additionally, we verify the effectiveness of statistical inference by GCT.
2023,
53(11):
1103.
doi: 10.52396/JUSTC-2022-0179
Abstract:
From a statistical viewpoint, it is essential to perform statistical inference in federated learning to understand the underlying data distribution. Due to the heterogeneity in the number of local iterations and in local datasets, traditional statistical inference methods are not competent in federated learning. This paper studies how to construct confidence intervals for federated heterogeneous optimization problems. We introduce the rescaled federated averaging estimate and prove the consistency of the estimate. Focusing on confidence interval estimation, we establish the asymptotic normality of the parameter estimate produced by our algorithm and show that the asymptotic covariance is inversely proportional to the client participation rate. We propose an online confidence interval estimation method called separated plug-in via rescaled federated averaging. This method can construct valid confidence intervals online when the number of local iterations is different across clients. Since there are variations in clients and local datasets, the heterogeneity in the number of local iterations is common. Consequently, confidence interval estimation for federated heterogeneous optimization problems is of great significance.
From a statistical viewpoint, it is essential to perform statistical inference in federated learning to understand the underlying data distribution. Due to the heterogeneity in the number of local iterations and in local datasets, traditional statistical inference methods are not competent in federated learning. This paper studies how to construct confidence intervals for federated heterogeneous optimization problems. We introduce the rescaled federated averaging estimate and prove the consistency of the estimate. Focusing on confidence interval estimation, we establish the asymptotic normality of the parameter estimate produced by our algorithm and show that the asymptotic covariance is inversely proportional to the client participation rate. We propose an online confidence interval estimation method called separated plug-in via rescaled federated averaging. This method can construct valid confidence intervals online when the number of local iterations is different across clients. Since there are variations in clients and local datasets, the heterogeneity in the number of local iterations is common. Consequently, confidence interval estimation for federated heterogeneous optimization problems is of great significance.

2023,
53(11):
1104.
doi: 10.52396/JUSTC-2023-0082
Abstract:
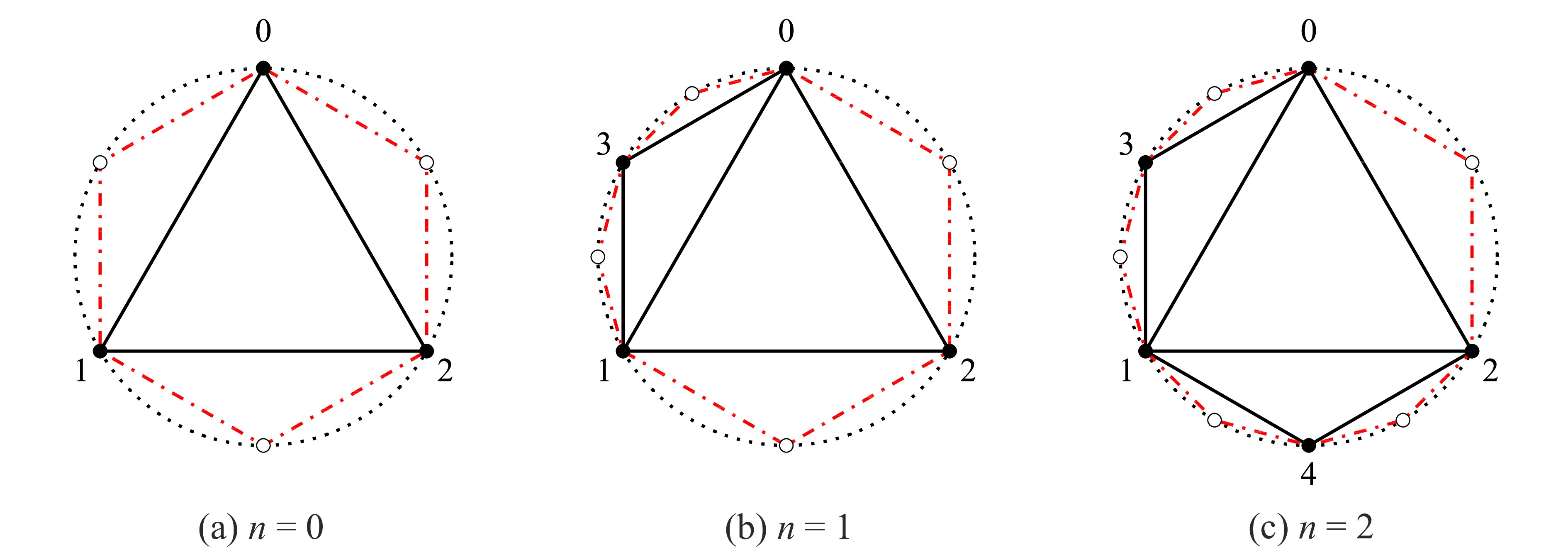
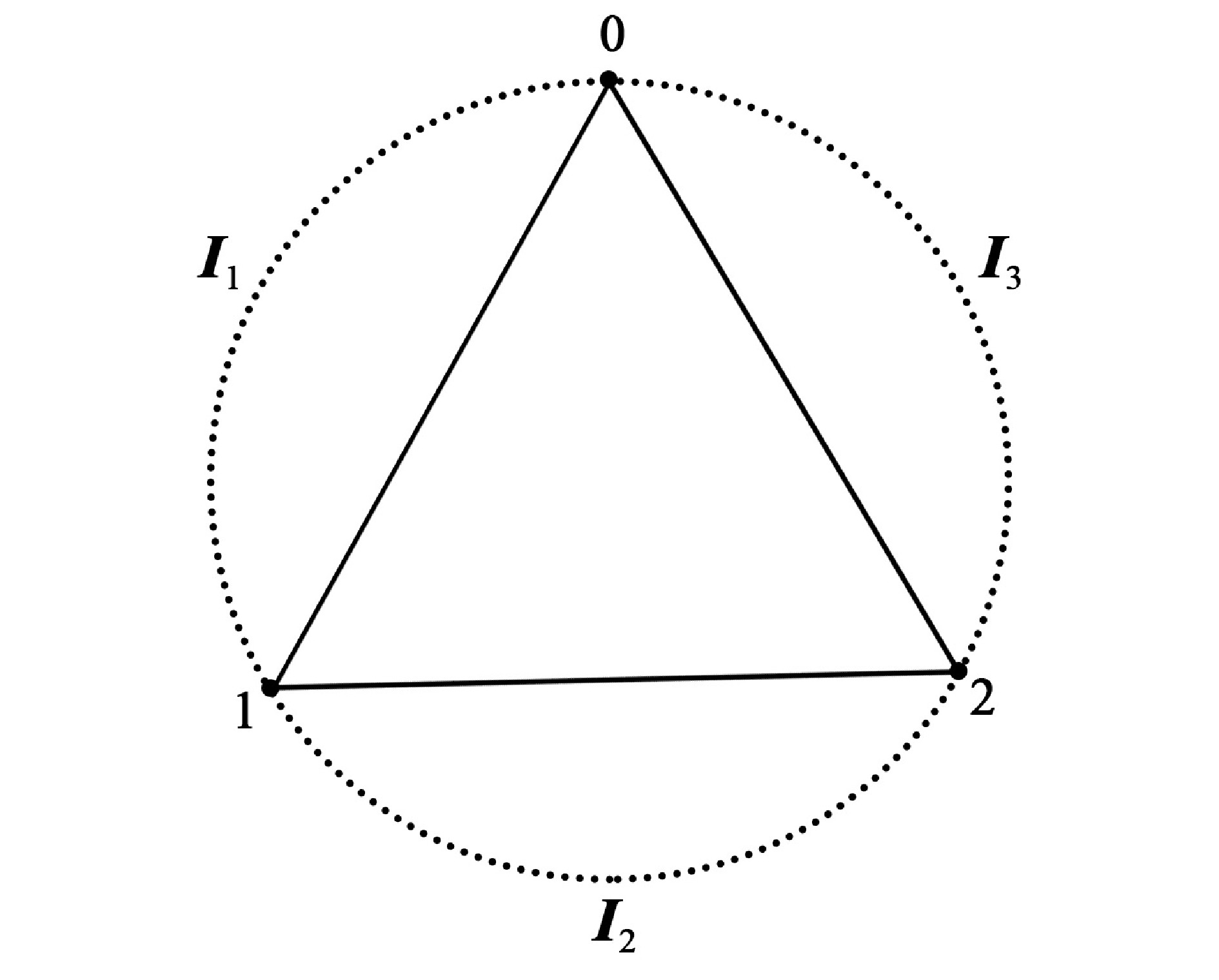
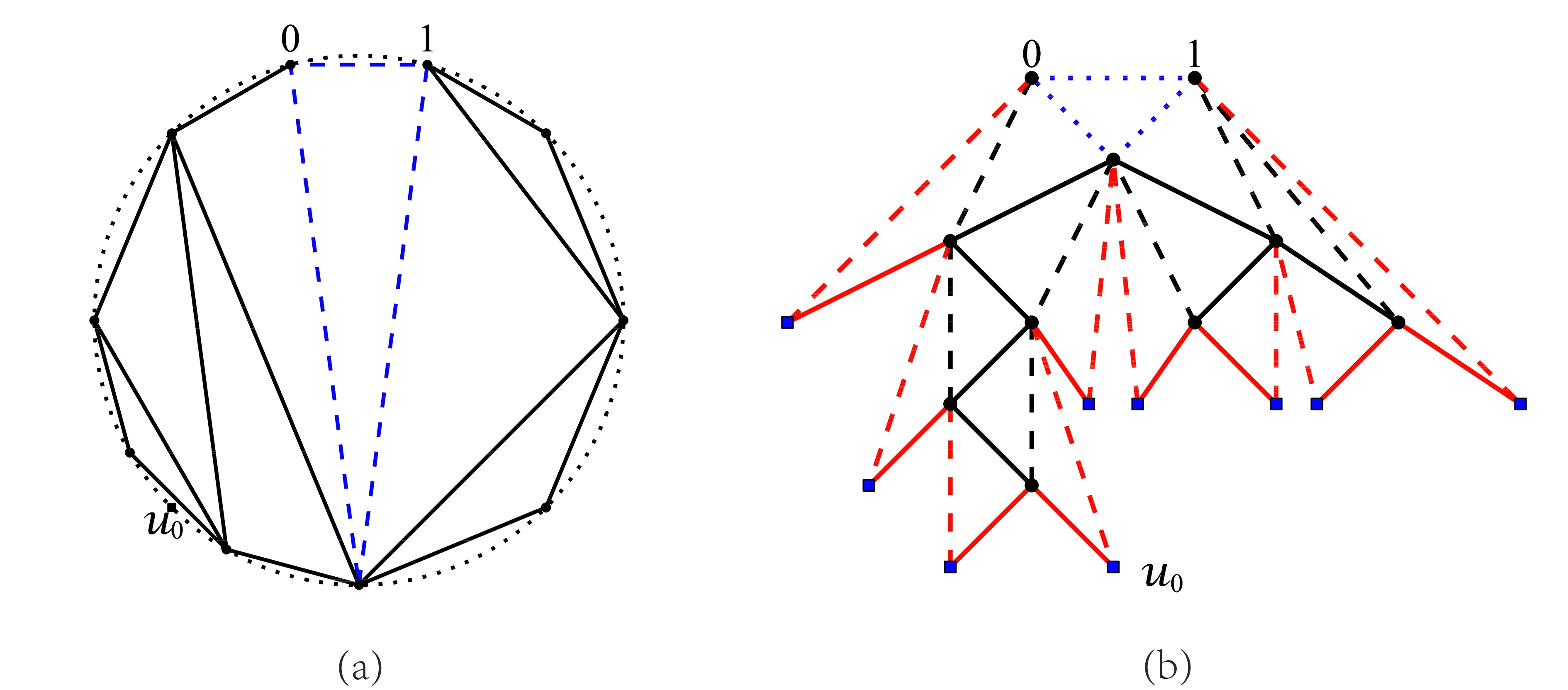
Distances between nodes are one of the most essential subjects in the study of complex networks. In this paper, we investigate the asymptotic behaviors of two types of distances in a model of geographic attachment networks (GANs): the typical distance and the flooding time. By generating an auxiliary tree and using a continuous-time branching process, we demonstrate that in this model the typical distance is asymptotically normal, and the flooding time converges to a given constant in probability as well.
Distances between nodes are one of the most essential subjects in the study of complex networks. In this paper, we investigate the asymptotic behaviors of two types of distances in a model of geographic attachment networks (GANs): the typical distance and the flooding time. By generating an auxiliary tree and using a continuous-time branching process, we demonstrate that in this model the typical distance is asymptotically normal, and the flooding time converges to a given constant in probability as well.
2023,
53(11):
1105.
doi: 10.52396/JUSTC-2022-0108
Abstract:
It is well known that regression methods designed for clean data will lead to erroneous results if directly applied to corrupted data. Despite the recent methodological and algorithmic advances in Gaussian graphical model estimation, how to achieve efficient and scalable estimation under contaminated covariates is unclear. Here a new methodology called convex conditioned innovative scalable efficient estimation (COCOISEE) for Gaussian graphical models under both additive and multiplicative measurement errors is developed. It combines the strengths of the innovative scalable efficient estimation in the Gaussian graphical model and the nearest positive semidefinite matrix projection, thus enjoying stepwise convexity and scalability. Comprehensive theoretical guarantees are provided and the effectiveness of the proposed methodology is demonstrated through numerical studies.
It is well known that regression methods designed for clean data will lead to erroneous results if directly applied to corrupted data. Despite the recent methodological and algorithmic advances in Gaussian graphical model estimation, how to achieve efficient and scalable estimation under contaminated covariates is unclear. Here a new methodology called convex conditioned innovative scalable efficient estimation (COCOISEE) for Gaussian graphical models under both additive and multiplicative measurement errors is developed. It combines the strengths of the innovative scalable efficient estimation in the Gaussian graphical model and the nearest positive semidefinite matrix projection, thus enjoying stepwise convexity and scalability. Comprehensive theoretical guarantees are provided and the effectiveness of the proposed methodology is demonstrated through numerical studies.
2023,
53(11):
1106.
doi: 10.52396/JUSTC-2023-0016
Abstract:
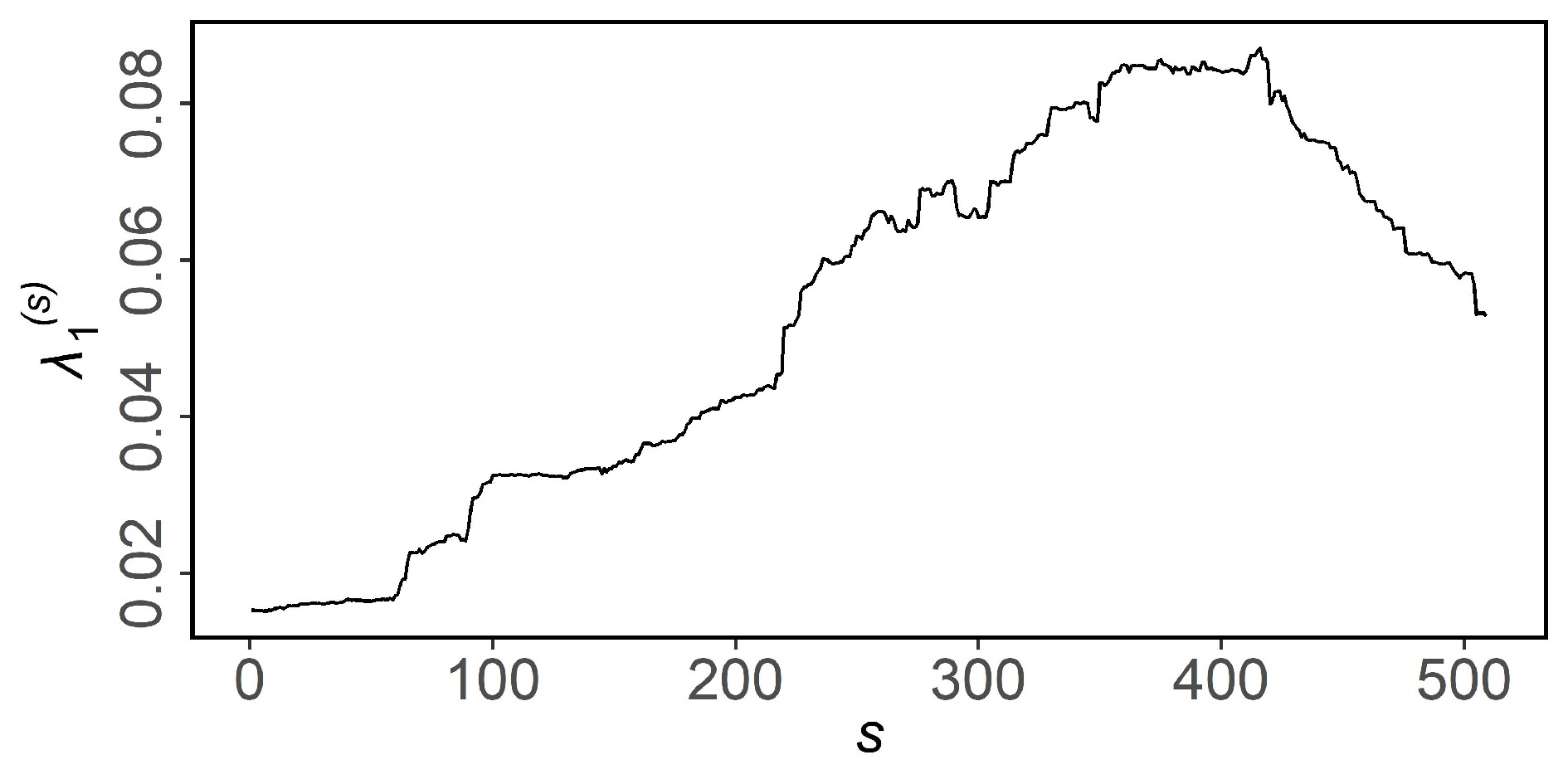
We consider the fluctuation of eigenvalues in factor models and propose a new method for testing the model. Based on the characteristics of eigenvalues, variables of unknown distribution are transformed into statistics of known distribution through randomization. The test statistic checks for breaks in the structure of factor models, including changes in factor loadings and increases in the number of factors. We give the results of simulation experiments and test the factor structure of the stock return data of China’s and U.S. stock markets from January 1, 2017, to December 31, 2019. Our method performs well in both simulations and real data.
We consider the fluctuation of eigenvalues in factor models and propose a new method for testing the model. Based on the characteristics of eigenvalues, variables of unknown distribution are transformed into statistics of known distribution through randomization. The test statistic checks for breaks in the structure of factor models, including changes in factor loadings and increases in the number of factors. We give the results of simulation experiments and test the factor structure of the stock return data of China’s and U.S. stock markets from January 1, 2017, to December 31, 2019. Our method performs well in both simulations and real data.
2023,
53(7):
0707.
doi: 10.52396/JUSTC-2023-0033
Abstract:
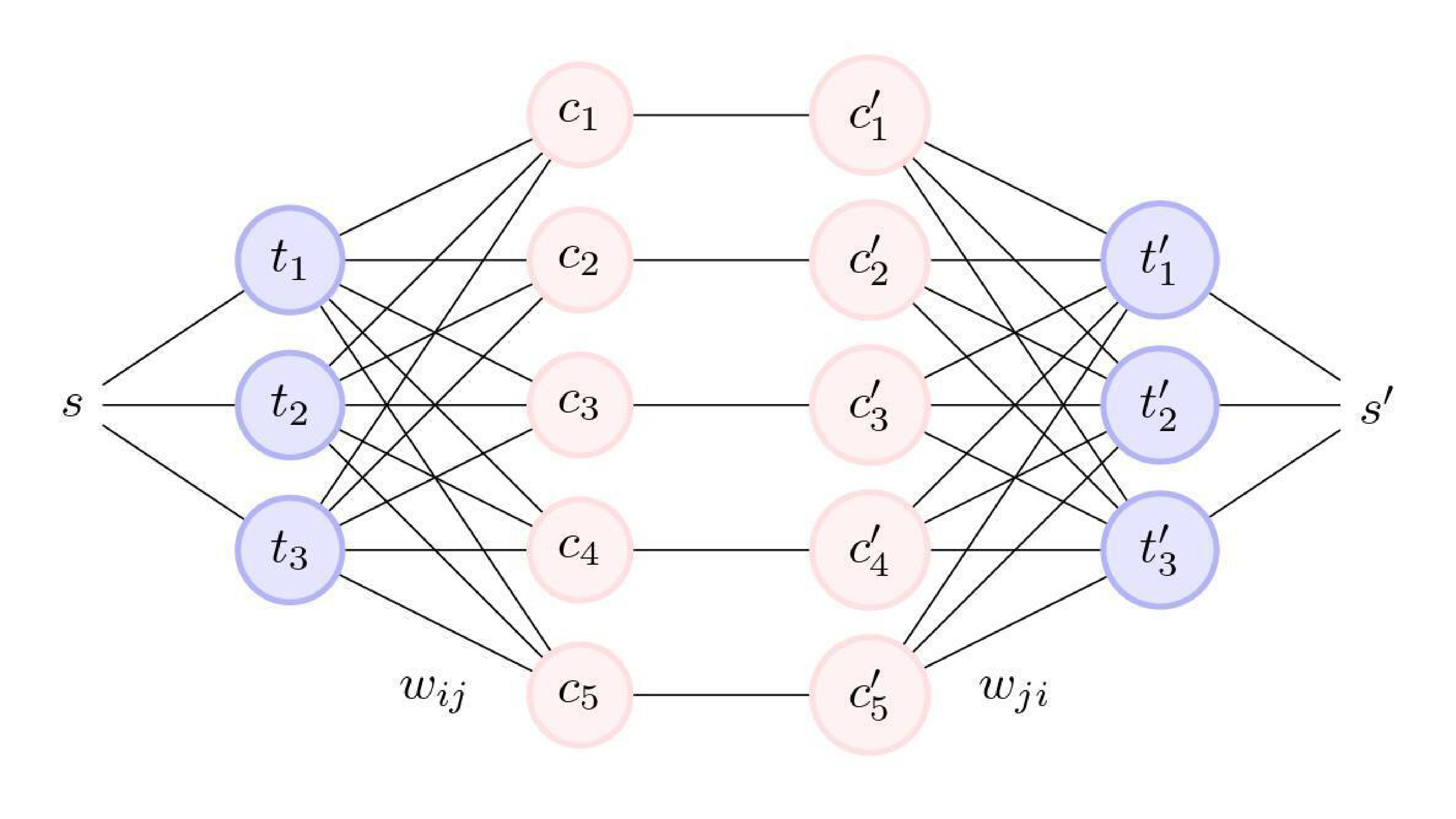
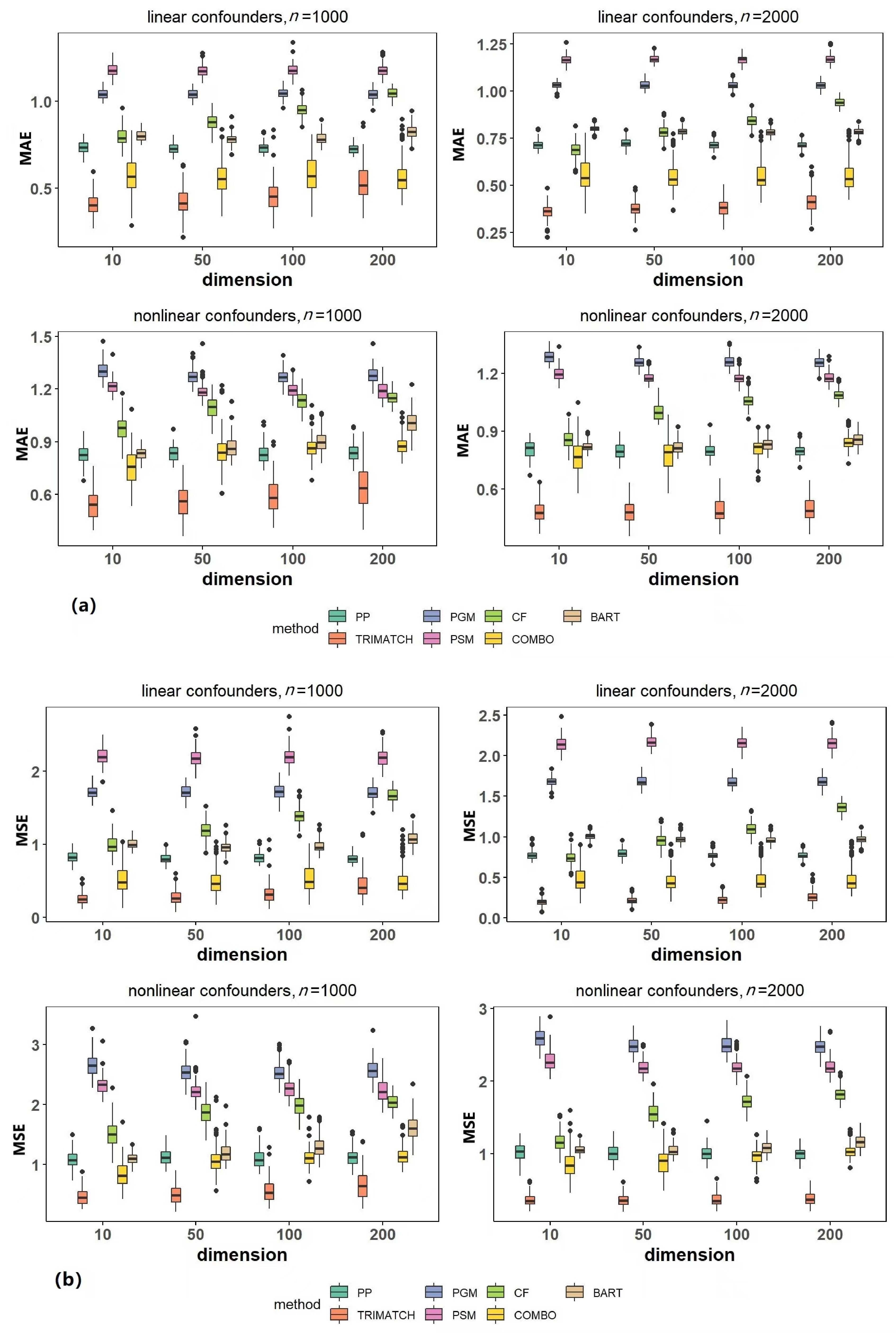
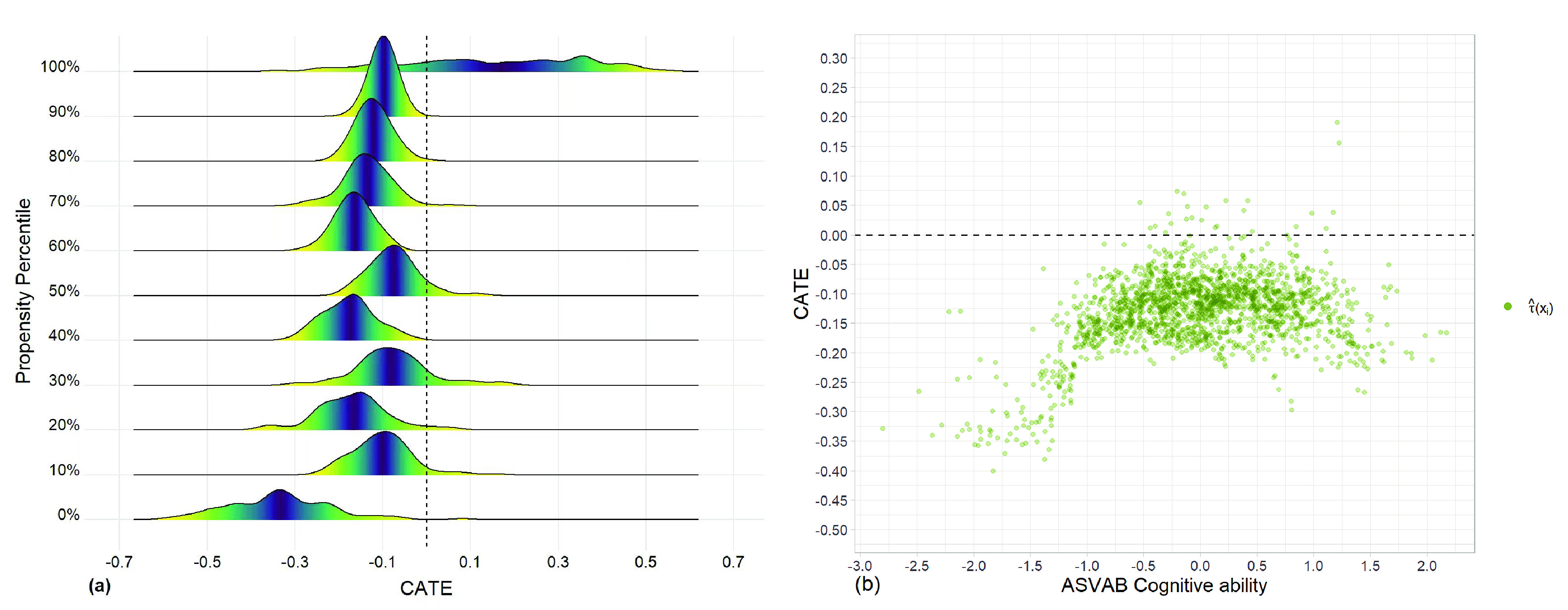
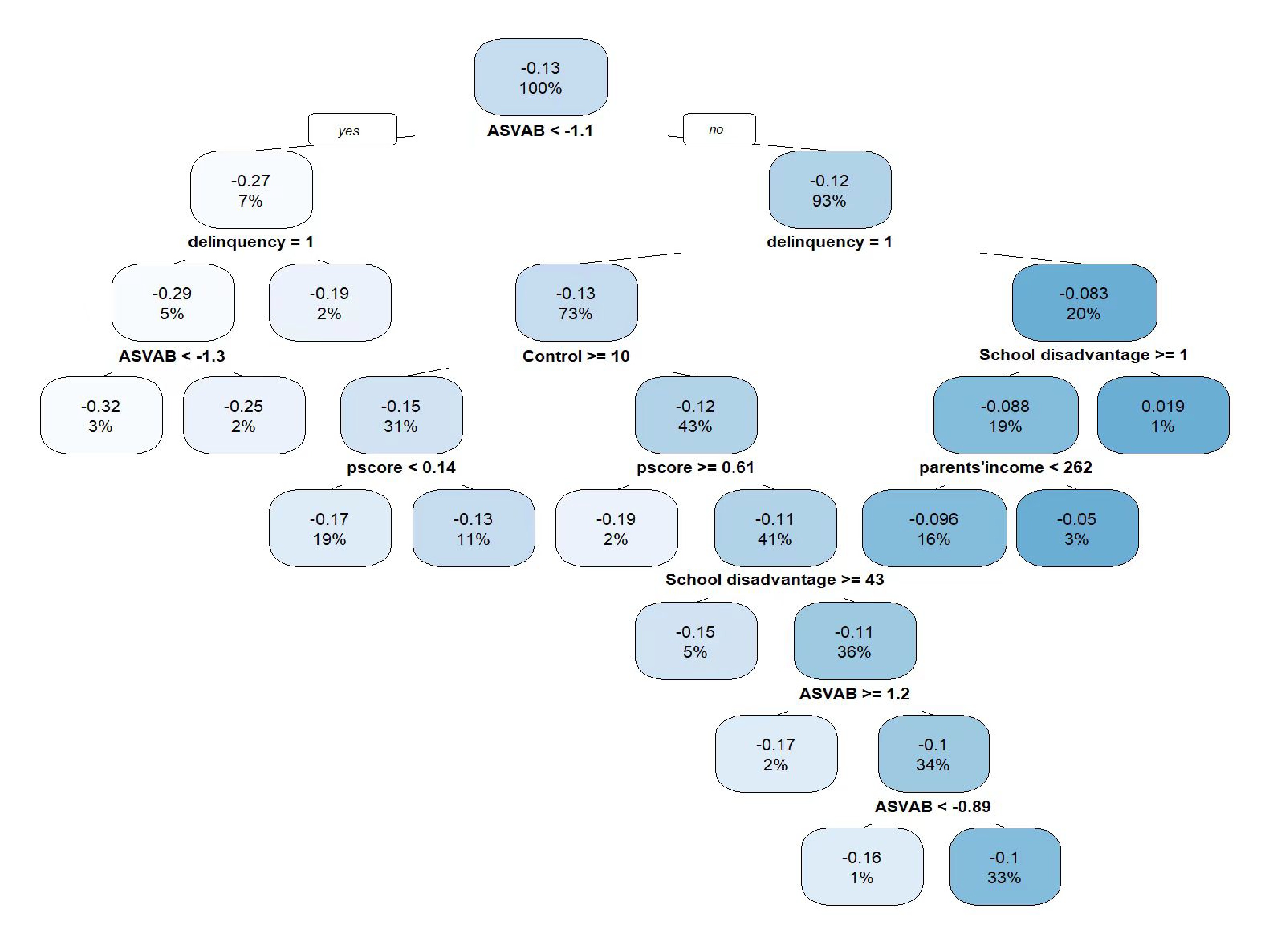
In observational studies, identifying subgroups and exploring heterogeneity is of practical significance. However, causal inference at the individual level is a challenging problem due to the absence of counterfactual outcomes and the presence of selection bias. To address this issue, we propose a general framework called TRIMATCH for estimating heterogeneous treatment effects. First, we find the optimal matching by solving a minimum average cost flow optimization problem in a tripartite graph network structure. Second, with the pseudo individual treatment effects acquired from the previous step, we establish a nonparametric regression model to predict heterogeneous treatment effects for individuals with diverse characteristics. Our experiments demonstrate the effectiveness of the proposed matching method and the interpretability of the results.
In observational studies, identifying subgroups and exploring heterogeneity is of practical significance. However, causal inference at the individual level is a challenging problem due to the absence of counterfactual outcomes and the presence of selection bias. To address this issue, we propose a general framework called TRIMATCH for estimating heterogeneous treatment effects. First, we find the optimal matching by solving a minimum average cost flow optimization problem in a tripartite graph network structure. Second, with the pseudo individual treatment effects acquired from the previous step, we establish a nonparametric regression model to predict heterogeneous treatment effects for individuals with diverse characteristics. Our experiments demonstrate the effectiveness of the proposed matching method and the interpretability of the results.
2023,
53(5):
0504.
doi: 10.52396/JUSTC-2022-0114
Abstract:
Some new types of mean value formulas for the polyharmonic functions were established. Based on the formulas, the Harnack inequality for the nonnegative solutions to the polyharmonic equations was proved.
Some new types of mean value formulas for the polyharmonic functions were established. Based on the formulas, the Harnack inequality for the nonnegative solutions to the polyharmonic equations was proved.
- First
- Prev
- 1
- 2
- 3
- 4
- 5
- Next
- Last
- Total:5
- To
- Go


