| [1] |
He X, Liao L, Zhang H, et al. Neural collaborative filtering. In: WWW’17: Proceedings of the 26th International Conference on World Wide Web. Perth, Australia: ACM, 2017: 173–182.
|
| [2] |
Yuan F, He X, Karatzoglou A, et al. Parameter-efficient transfer from sequential behaviors for user modeling and recommendation. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 1469–1478.
|
| [3] |
Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM, 2019: 1441–1450.
|
| [4] |
Abdollahpouri H, Burke R, Mobasher B. Controlling popularity bias in learning-to-rank recommendation. In: Proceedings of the Eleventh ACM Conference on Recommender Systems. New York: ACM, 2017: 42–46.
|
| [5] |
Liu D, Cheng P, Dong Z, et al. A general knowledge distillation framework for counterfactual recommendation via uniform data. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 831–840.
|
| [6] |
Schnabel T, Swaminathan A, Singh A, et al. Recommendations as treatments: Debiasing learning and evaluation. In: Proceedings of the 33rd International Conference on Machine Learning. New York: ACM, 2016: 1670–1679.
|
| [7] |
Wang X, Bendersky M, Metzler D, et al. Learning to rank with selection bias in personal search. In: Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. New York: ACM, 2016: 115–124.
|
| [8] |
Hernández-Lobato J M, Houlsby N, Ghahramani Z. Probabilistic matrix factorization with non-random missing data. In: Proceedings of the 31st International Conference on International Conference on Machine Learning-Volume 32. New York: ACM, 2014: II-1512–II-1520.
|
| [9] |
Steck H. Evaluation of recommendations: Rating-prediction and ranking. In: Proceedings of the 7th ACM Conference on Recommender Systems. New York: ACM, 2013: 213–220.
|
| [10] |
Chen J, Dong H, Qiu Y, et al. AutoDebias: Learning to debias for recommendation. In: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 21–30.
|
| [11] |
Chen J, Dong H, Wang X, et al. Bias and debias in recommender system: A survey and future directions. ACM Transactions on Information Systems, 2023, 41: 1–39. doi: 10.1145/3564284
|
| [12] |
Marlin B, Zemel R S, Roweis S, et al. Collaborative filtering and the missing at random assumption. arXiv: 1206.5267, 2012.
|
| [13] |
Steck H. Training and testing of recommender systems on data missing not at random. In: Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2010: 713–722.
|
| [14] |
Krishnan S, Patel J, Franklin M J, et al. A methodology for learning, analyzing, and mitigating social influence bias in recommender systems. In: Proceedings of the 8th ACM Conference on Recommender Systems. New York: ACM, 2014: 137–144.
|
| [15] |
Liu Y, Cao X, Yu Y. Are you influenced by others when rating? Improve rating prediction by conformity modeling. In: Proceedings of the 10th ACM Conference on Recommender Systems. New York: ACM, 2016: 269–272.
|
| [16] |
Tang J, Gao H, Liu H. mTrust: Discerning multi-faceted trust in a connected world. In: Proceedings of the Fifth ACM International Conference on Web Search and Data Mining. New York: ACM, 2012: 93–102.
|
| [17] |
Ma H, King I, Lyu M R. Learning to recommend with social trust ensemble. In: Proceedings of the 32nd international ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2009: 203–210.
|
| [18] |
Hu Y, Koren Y, Volinsky C. Collaborative filtering for implicit feedback datasets. In: 2008 Eighth IEEE International Conference on Data Mining. Pisa, Italy: IEEE, 2008: 263–272.
|
| [19] |
Pan R, Scholz M. Mind the gaps: Weighting the unknown in large-scale one-class collaborative filtering. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). New York: ACM, 2009: 667–676.
|
| [20] |
Chen J, Wang C, Zhou S, et al. Fast adaptively weighted matrix factorization for recommendation with implicit feedback. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34: 3470–3477. doi: 10.1609/aaai.v34i04.5751
|
| [21] |
Dupret G E, Piwowarski B. A user browsing model to predict search engine click data from past observations. In: Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Singapore: ACM, 2008: 331–338.
|
| [22] |
Zhang W V, Jones R. Comparing click logs and editorial labels for training query rewriting. In: WWW 2007 Workshop on Query Log Analysis: Social And Technological Challenges. Banff, Canada: ACM, 2007: 43.
|
| [23] |
Craswell N, Zoeter O, Taylor M, et al. An experimental comparison of click position-bias models. In: Proceedings of the 2008 International Conference on Web Search and Data Mining. New York: ACM, 2008: 87–94.
|
| [24] |
Guo F, Liu C, Kannan A, et al. Click chain model in web search. In: Proceedings of the 18th International Conference on World Wide Web. New York: ACM, 2009: 11–20.
|
| [25] |
Zhu Z A, Chen W, Minka T, et al. A novel click model and its applications to online advertising. In: Proceedings of the Third ACM International Conference on Web Search and Data Mining. New York: ACM, 2010: 321–330.
|
| [26] |
Kamishima T, Akaho S, Asoh H, et al. Correcting popularity bias by enhancing recommendation neutrality. In: Proceedings of the 8th ACM Conference on Recommender Systems. Foster City, USA: ACM, 2014.
|
| [27] |
Zheng Y, Gao C, Li X, et al. Disentangling user interest and conformity for recommendation with causal embedding. In: Proceedings of the Web Conference 2021. New York: ACM, 2021: 2980–2991.
|
| [28] |
Krishnan A, Sharma A, Sankar A, et al. An adversarial approach to improve long-tail performance in neural collaborative filtering. In: Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 1491–1494.
|
| [29] |
Rendle S, Freudenthaler C, Gantner Z, et al. BPR: Bayesian personalized ranking from implicit feedback. In: Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence. Montreal, Canada: AUAI Press, 2009: 452–461.
|
| [30] |
Wu Y, DuBois C, Zheng A X, et al. Collaborative denoising auto-encoders for top-N recommender systems. In: Proceedings of the Ninth ACM International Conference on Web Search and Data Mining. San Francisco, USA: ACM, 2016: 153–162.
|
| [31] |
He X, Deng K, Wang X, et al. LightGCN: Simplifying and powering graph convolution network for recommendation. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Xi’an, China: ACM, 2020: 639–648.
|
| [32] |
He X, Du X, Wang X, et al. Outer product-based neural collaborative filtering. In: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence. Stockholm, Sweden: IJCAI Organization, 2018: 2227–2233.
|
| [33] |
Yu H-F, Bilenko M, Lin C-J. Selection of negative samples for one-class matrix factorization. In: Proceedings of the 2017 SIAM International Conference on Data Mining. Houston, USA: SIAM, 2017: 363–371.
|
| [34] |
Park D H, Chang Y. Adversarial sampling and training for semi-supervised information retrieval. In: WWW’19: The World Wide Web Conference. New York: ACM, 2019: 1443–1453.
|
| [35] |
Rendle S, Freudenthaler C. Improving pairwise learning for item recommendation from implicit feedback. In: WSDM’14: Proceedings of the Seventh ACM International Conference on Web Search and Data Mining. New York, USA: ACM, 2014: 273–282.
|
| [36] |
Ding J, Quan Y, He X, et al. Reinforced negative sampling for recommendation with exposure data. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. Macao, China: IJCAI Organization, 2019: 2230–2236.
|
| [37] |
Ding J, Feng F, He X, et al. An improved sampler for Bayesian personalized ranking by leveraging view data. In: Companion Proceedings of The Web Conference 2018. Lyon, France: ACM, 2018: 13–14.
|
| [38] |
Chen J, Wang C, Zhou S, et al. SamWalker: Social recommendation with informative sampling strategy. In: WWW’19: The World Wide Web Conference. New York: ACM, 2019: 228–239.
|
| [39] |
Haussler D. Probably Approximately Correct Learning. Palo Alto, USA: AAAI Press, 1990.
|
| [40] |
Sun W, Khenissi S, Nasraoui O, et al. Debiasing the human-recommender system feedback loop in collaborative filtering. In: WWW’19: The World Wide Web Conference. San Francisco, USA: ACM, 2019: 645–651.
|
| [41] |
Gleich D F, Lim L H. Rank aggregation via nuclear norm minimization. In: KDD’11: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego, USA: ACM, 2011: 60–68.
|
| [42] |
Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems. Computer, 2009, 42: 30–37. doi: 10.1109/mc.2009.263
|
| [43] |
Wang X, Zhang R, Sun Y, et al. Doubly robust joint learning for recommendation on data missing not at random. In: ICML’19: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019: 6638–6647.
|
| [44] |
Ai Q, Bi K, Luo C, et al. Unbiased learning to rank with unbiased propensity estimation. In: SIGIR’18: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. New York: ACM, 2018: 385–394.
|
| [45] |
Ovaisi Z, Ahsan R, Zhang Y, et al. Correcting for selection bias in learning-to-rank systems. In: Proceedings of The Web Conference 2020. New York: ACM, 2020: 1863–1873.
|
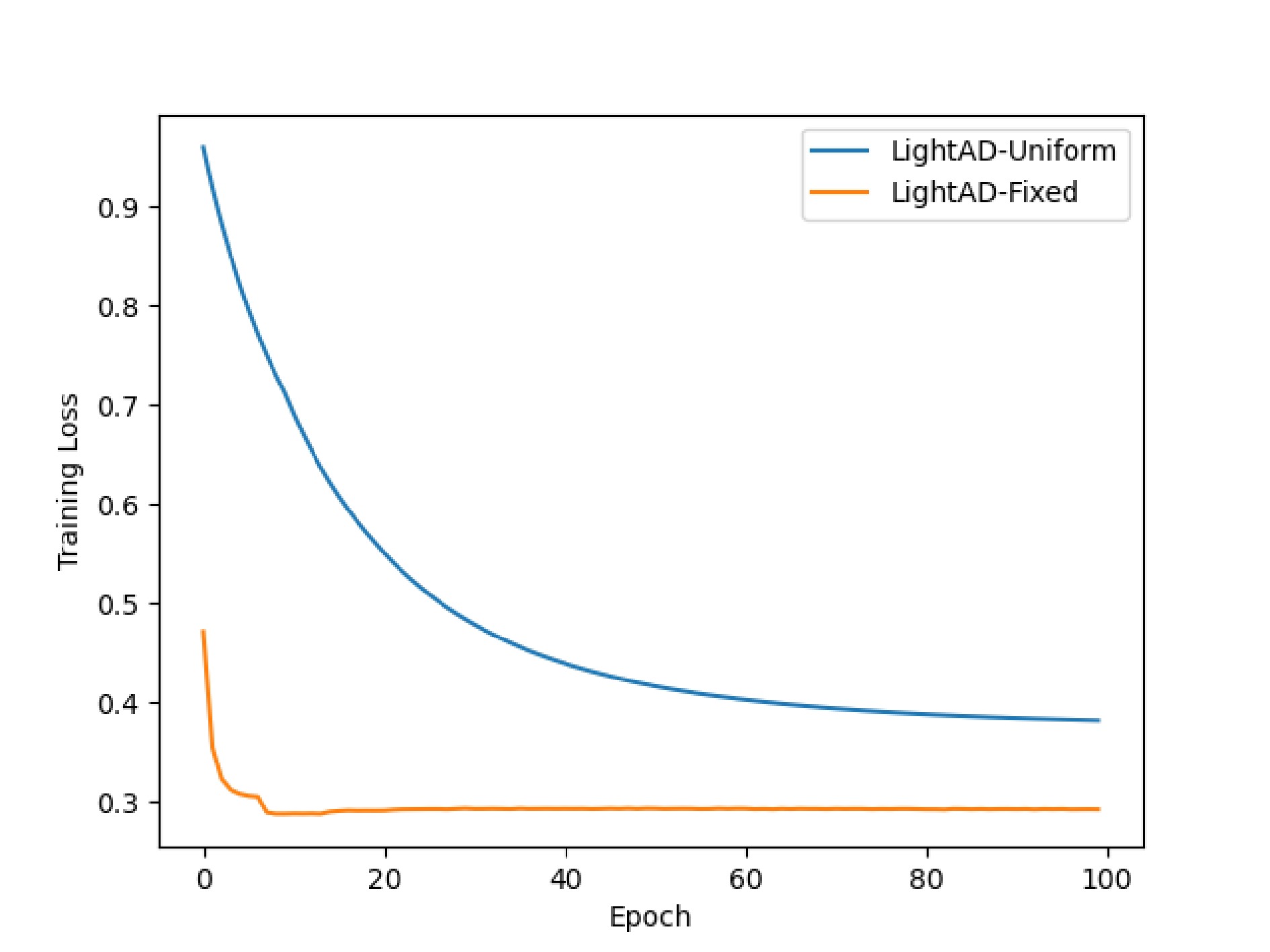
Figure 1. Training process of LightAD-fixed and LightAD-uniform.
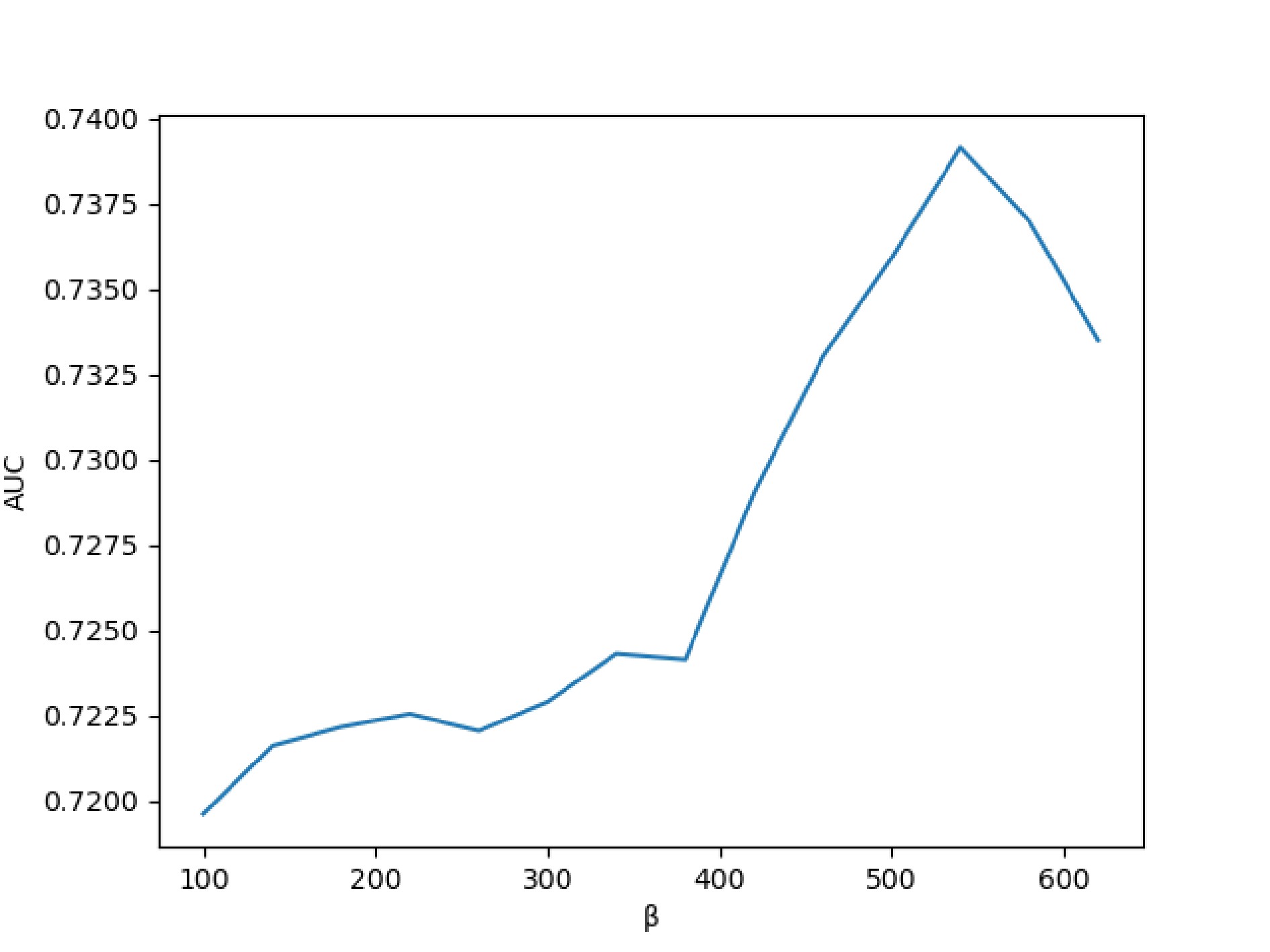
Figure 2. The influence of hyperparameter β on self-paced sampling strategy.
| [1] |
He X, Liao L, Zhang H, et al. Neural collaborative filtering. In: WWW’17: Proceedings of the 26th International Conference on World Wide Web. Perth, Australia: ACM, 2017: 173–182.
|
| [2] |
Yuan F, He X, Karatzoglou A, et al. Parameter-efficient transfer from sequential behaviors for user modeling and recommendation. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 1469–1478.
|
| [3] |
Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management. New York: ACM, 2019: 1441–1450.
|
| [4] |
Abdollahpouri H, Burke R, Mobasher B. Controlling popularity bias in learning-to-rank recommendation. In: Proceedings of the Eleventh ACM Conference on Recommender Systems. New York: ACM, 2017: 42–46.
|
| [5] |
Liu D, Cheng P, Dong Z, et al. A general knowledge distillation framework for counterfactual recommendation via uniform data. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 831–840.
|
| [6] |
Schnabel T, Swaminathan A, Singh A, et al. Recommendations as treatments: Debiasing learning and evaluation. In: Proceedings of the 33rd International Conference on Machine Learning. New York: ACM, 2016: 1670–1679.
|
| [7] |
Wang X, Bendersky M, Metzler D, et al. Learning to rank with selection bias in personal search. In: Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. New York: ACM, 2016: 115–124.
|
| [8] |
Hernández-Lobato J M, Houlsby N, Ghahramani Z. Probabilistic matrix factorization with non-random missing data. In: Proceedings of the 31st International Conference on International Conference on Machine Learning-Volume 32. New York: ACM, 2014: II-1512–II-1520.
|
| [9] |
Steck H. Evaluation of recommendations: Rating-prediction and ranking. In: Proceedings of the 7th ACM Conference on Recommender Systems. New York: ACM, 2013: 213–220.
|
| [10] |
Chen J, Dong H, Qiu Y, et al. AutoDebias: Learning to debias for recommendation. In: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2021: 21–30.
|
| [11] |
Chen J, Dong H, Wang X, et al. Bias and debias in recommender system: A survey and future directions. ACM Transactions on Information Systems, 2023, 41: 1–39. doi: 10.1145/3564284
|
| [12] |
Marlin B, Zemel R S, Roweis S, et al. Collaborative filtering and the missing at random assumption. arXiv: 1206.5267, 2012.
|
| [13] |
Steck H. Training and testing of recommender systems on data missing not at random. In: Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2010: 713–722.
|
| [14] |
Krishnan S, Patel J, Franklin M J, et al. A methodology for learning, analyzing, and mitigating social influence bias in recommender systems. In: Proceedings of the 8th ACM Conference on Recommender Systems. New York: ACM, 2014: 137–144.
|
| [15] |
Liu Y, Cao X, Yu Y. Are you influenced by others when rating? Improve rating prediction by conformity modeling. In: Proceedings of the 10th ACM Conference on Recommender Systems. New York: ACM, 2016: 269–272.
|
| [16] |
Tang J, Gao H, Liu H. mTrust: Discerning multi-faceted trust in a connected world. In: Proceedings of the Fifth ACM International Conference on Web Search and Data Mining. New York: ACM, 2012: 93–102.
|
| [17] |
Ma H, King I, Lyu M R. Learning to recommend with social trust ensemble. In: Proceedings of the 32nd international ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2009: 203–210.
|
| [18] |
Hu Y, Koren Y, Volinsky C. Collaborative filtering for implicit feedback datasets. In: 2008 Eighth IEEE International Conference on Data Mining. Pisa, Italy: IEEE, 2008: 263–272.
|
| [19] |
Pan R, Scholz M. Mind the gaps: Weighting the unknown in large-scale one-class collaborative filtering. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). New York: ACM, 2009: 667–676.
|
| [20] |
Chen J, Wang C, Zhou S, et al. Fast adaptively weighted matrix factorization for recommendation with implicit feedback. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34: 3470–3477. doi: 10.1609/aaai.v34i04.5751
|
| [21] |
Dupret G E, Piwowarski B. A user browsing model to predict search engine click data from past observations. In: Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Singapore: ACM, 2008: 331–338.
|
| [22] |
Zhang W V, Jones R. Comparing click logs and editorial labels for training query rewriting. In: WWW 2007 Workshop on Query Log Analysis: Social And Technological Challenges. Banff, Canada: ACM, 2007: 43.
|
| [23] |
Craswell N, Zoeter O, Taylor M, et al. An experimental comparison of click position-bias models. In: Proceedings of the 2008 International Conference on Web Search and Data Mining. New York: ACM, 2008: 87–94.
|
| [24] |
Guo F, Liu C, Kannan A, et al. Click chain model in web search. In: Proceedings of the 18th International Conference on World Wide Web. New York: ACM, 2009: 11–20.
|
| [25] |
Zhu Z A, Chen W, Minka T, et al. A novel click model and its applications to online advertising. In: Proceedings of the Third ACM International Conference on Web Search and Data Mining. New York: ACM, 2010: 321–330.
|
| [26] |
Kamishima T, Akaho S, Asoh H, et al. Correcting popularity bias by enhancing recommendation neutrality. In: Proceedings of the 8th ACM Conference on Recommender Systems. Foster City, USA: ACM, 2014.
|
| [27] |
Zheng Y, Gao C, Li X, et al. Disentangling user interest and conformity for recommendation with causal embedding. In: Proceedings of the Web Conference 2021. New York: ACM, 2021: 2980–2991.
|
| [28] |
Krishnan A, Sharma A, Sankar A, et al. An adversarial approach to improve long-tail performance in neural collaborative filtering. In: Proceedings of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM, 2018: 1491–1494.
|
| [29] |
Rendle S, Freudenthaler C, Gantner Z, et al. BPR: Bayesian personalized ranking from implicit feedback. In: Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence. Montreal, Canada: AUAI Press, 2009: 452–461.
|
| [30] |
Wu Y, DuBois C, Zheng A X, et al. Collaborative denoising auto-encoders for top-N recommender systems. In: Proceedings of the Ninth ACM International Conference on Web Search and Data Mining. San Francisco, USA: ACM, 2016: 153–162.
|
| [31] |
He X, Deng K, Wang X, et al. LightGCN: Simplifying and powering graph convolution network for recommendation. In: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. Xi’an, China: ACM, 2020: 639–648.
|
| [32] |
He X, Du X, Wang X, et al. Outer product-based neural collaborative filtering. In: Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence. Stockholm, Sweden: IJCAI Organization, 2018: 2227–2233.
|
| [33] |
Yu H-F, Bilenko M, Lin C-J. Selection of negative samples for one-class matrix factorization. In: Proceedings of the 2017 SIAM International Conference on Data Mining. Houston, USA: SIAM, 2017: 363–371.
|
| [34] |
Park D H, Chang Y. Adversarial sampling and training for semi-supervised information retrieval. In: WWW’19: The World Wide Web Conference. New York: ACM, 2019: 1443–1453.
|
| [35] |
Rendle S, Freudenthaler C. Improving pairwise learning for item recommendation from implicit feedback. In: WSDM’14: Proceedings of the Seventh ACM International Conference on Web Search and Data Mining. New York, USA: ACM, 2014: 273–282.
|
| [36] |
Ding J, Quan Y, He X, et al. Reinforced negative sampling for recommendation with exposure data. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence. Macao, China: IJCAI Organization, 2019: 2230–2236.
|
| [37] |
Ding J, Feng F, He X, et al. An improved sampler for Bayesian personalized ranking by leveraging view data. In: Companion Proceedings of The Web Conference 2018. Lyon, France: ACM, 2018: 13–14.
|
| [38] |
Chen J, Wang C, Zhou S, et al. SamWalker: Social recommendation with informative sampling strategy. In: WWW’19: The World Wide Web Conference. New York: ACM, 2019: 228–239.
|
| [39] |
Haussler D. Probably Approximately Correct Learning. Palo Alto, USA: AAAI Press, 1990.
|
| [40] |
Sun W, Khenissi S, Nasraoui O, et al. Debiasing the human-recommender system feedback loop in collaborative filtering. In: WWW’19: The World Wide Web Conference. San Francisco, USA: ACM, 2019: 645–651.
|
| [41] |
Gleich D F, Lim L H. Rank aggregation via nuclear norm minimization. In: KDD’11: Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego, USA: ACM, 2011: 60–68.
|
| [42] |
Koren Y, Bell R, Volinsky C. Matrix factorization techniques for recommender systems. Computer, 2009, 42: 30–37. doi: 10.1109/mc.2009.263
|
| [43] |
Wang X, Zhang R, Sun Y, et al. Doubly robust joint learning for recommendation on data missing not at random. In: ICML’19: Proceedings of the 36th International Conference on Machine Learning. Long Beach, USA: PMLR, 2019: 6638–6647.
|
| [44] |
Ai Q, Bi K, Luo C, et al. Unbiased learning to rank with unbiased propensity estimation. In: SIGIR’18: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. New York: ACM, 2018: 385–394.
|
| [45] |
Ovaisi Z, Ahsan R, Zhang Y, et al. Correcting for selection bias in learning-to-rank systems. In: Proceedings of The Web Conference 2020. New York: ACM, 2020: 1863–1873.
|

ISSN 0253-2778
CN 34-1054/N
Copyright © Editorial Office of JUSTC, All Rights Reserved. 皖ICP备05002528号
Supported by:
Beijing Renhe Information Technology Co. Ltd





 DownLoad:
DownLoad: